- Column
- 〔誌上体験〕IBM Garage流イノベーションの始め方
Operate:利用者視点でのサービス改善を前提に運用する【第11回】
サイトの可用性に責任を持つ
Design for Failureの考え方と共に「SRE(Site Reliability Engineering:サイト・リライアビリティ・エンジニアリング)」という考え方がある。設計したシステムの可用性やサービスの継続性に責任を持ち、改善を繰り返しながら運用するというものだ。従来の運用・保守では、サービスイン後は予め決定した手順書に従って運用し、リリース以降は現行の踏襲を前提としていた。
これに対しSREでは、サイトの可用性に責任を持つために、積極的な改善を継続的に実施する。SREにおいて興味深い考え方に「Error Budget(エラーバジェット)」と「Chaos Engineering(カオスエンジニアリング)」がある。
エラーバジェット
エラーバジェットとは、SREで定義するSLO(Service Level Objective:サービスレベル目標)に対する余裕率のことである。例えば、可能性が99.95%のサービスレベルを実現する際に、30日間に停止可能な時間は約21分である。この21分がエラーバジェットであり、開発担当者と運用・保守担当者にとっての合理的なKPI(Key Performance Indicator:重要業績管理指標)になる。
具体的には、「運用中に積算された停止時間が21分を越えた場合は新しいリリースを受け付けない」といった決まりを設けることで、開発側と運用・保守側がエラーバジェットの下で協力し合う体制が構築できる(図1)。
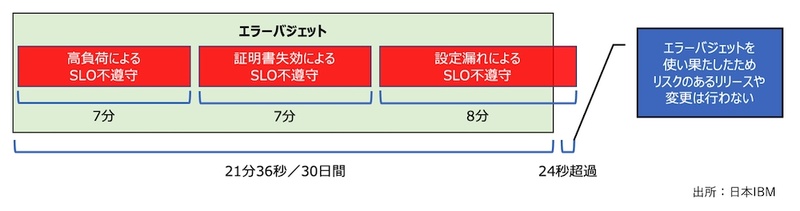
筆者の経験では、エラーバジェットは単純に作業の調整弁としての役割だけでなく、客観的指標に基づいたSLOの調整や課題の可視化につなげられる。例えば、エラーバジェットにより頻繁にリリースできない場合は、その頻度によりSLOと、プロセス/アーキテクチャー/品質のギャップに気づき改善策を立てる動機付けになるからだ。
カオスエンジニアリング
カオスエンジニアリングは、本番環境に“わざと”バグや負荷をかけるなどし、それでもサービスが停止しないことを確認する非常に大胆な手法である。開発環境でいくらテストをしても、本番になって初めて発生する問題は多数ある。カオスエンジニアリングのメリットは、それらを予めテストできることだ。
一方で、本番環境で検証した結果、サイトが全面ダウンするといったことは許されない。カオスエンジニアリングが実行できるのは、エラーバジェットやリリースのロールバック、マイクロサービスの適用など様々な条件が揃った環境のみである。
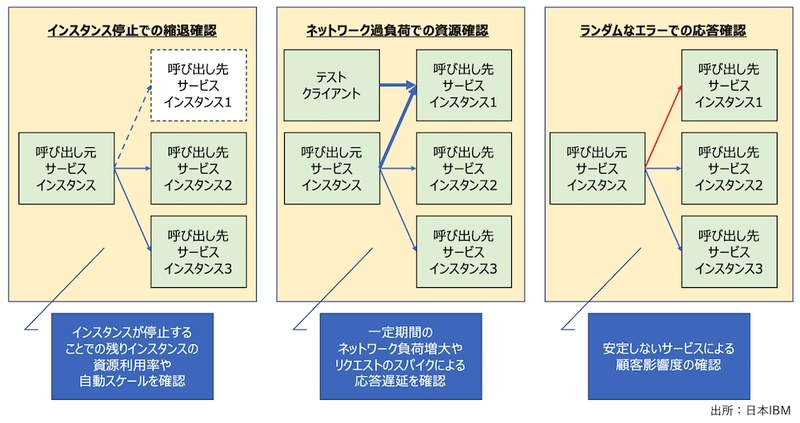
図2は、カオスエンジニアリングにおける3つのテストである(1)インスタンス停止状態での縮退確認、(2)ネットワーク過負荷での資源確認、(3)ランダムなエラーでの応答確認の方法を記載したものだ。
ミニ演習1
状況 :エラーバジェットを適用し運用しているが、バジェットが枯渇してリリースができなくなる状態が継続している。原理原則に従うとリリースはできないが、どうしてもリリースするためには、どのような対処が考えられるだろうか。
選択肢 :
アクションa :原理原則なのでリリースさせない
アクションb :リリース可能な例外ケースを定義する
アクションc :エラーバジェット枯渇の度に責任者やプロダクトオーナーと協議する
実際の現場では、セキュリティ事故やクラウド障害のワークアラウンド対応などが発生する。これらのケースでは、リリースできないことによるビジネスリスクが高く、アクションaの「リリースさせない」とい選択肢は取り得ない。
エラーバジェットの枯渇が頻繁に起こるということは、そもそもプロダクトの品質やリリース計画に問題がある。エラーバジェットの枯渇が継続的に発生するようであれば、アクションcにあるように、新機能の追加や機能改善を止めてでも品質を改善すべきかについて、プロダクトオーナーなどを含め協議する必要がある。
エラーバジェットが枯渇してもリリースできるようにするためには、アクションbに挙げたように、事前に例外的なパターンを取り決めておく。例外的なパターンを増やすとエラーバジェットの効果が薄くなるため、重要なセキュリティ事故などビジネス上のリスクが極大になるパターンに限定する。