- News
- サービス
正解データが少なくても学習できる機械学習技術、富士通研究所が開発
十分な学習用データがなくても高い精度で判定できる機械学習技術を富士通研究所が開発した。2018年9月19日に発表した。
富士通研究所が開発した「Wide Learning」は、正解数が少ないデータセットにおいても高精度で学習できる機械学習技術。機械学習では一般に、十分な量の正解を含む大量データを使って学習する。Wide Learningでは、すべてのデータ項目を単独ではなく組み合わせで判断することでデータ量が少なくても精度を高められるようにした。
たとえば、商品の購入傾向分析では、各データの「性別」「免許保有」「婚姻」「年齢」といったデータ項目を組み合わせて「仮説」とする。「女性で免許を保有している顧客」や「未婚で20~34歳」といった全パターンを組み合わせて仮説を作り、仮説ごとに実際の商品購入率(仮説のヒット率)を検証する(図1)。
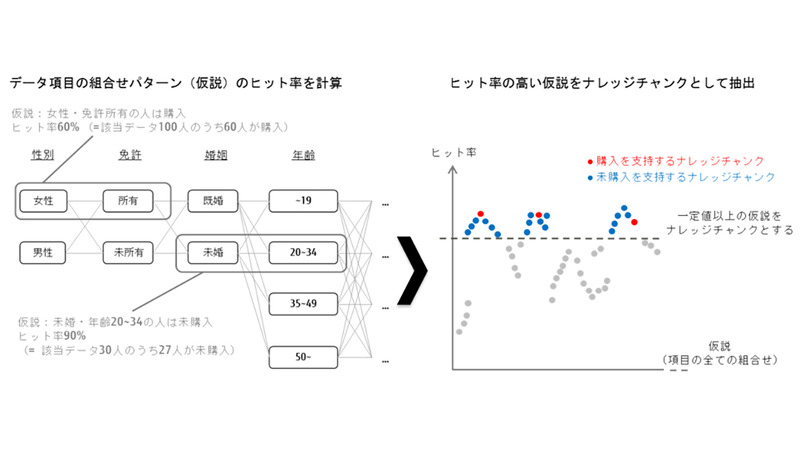
一定のヒット率を記録した仮説を「ナレッジチャンク」と呼び、重要な仮説に位置付ける。これにより、正解データが少ないデータセットであっても注目すべき仮説を抽出する。これまで考えつかなかった仮説の発見にもつながるという。ナレッジチャンクは、論理的な表現で記述できるため、人間でも機械学習の判断の根拠を理解しやすくなるともいう。
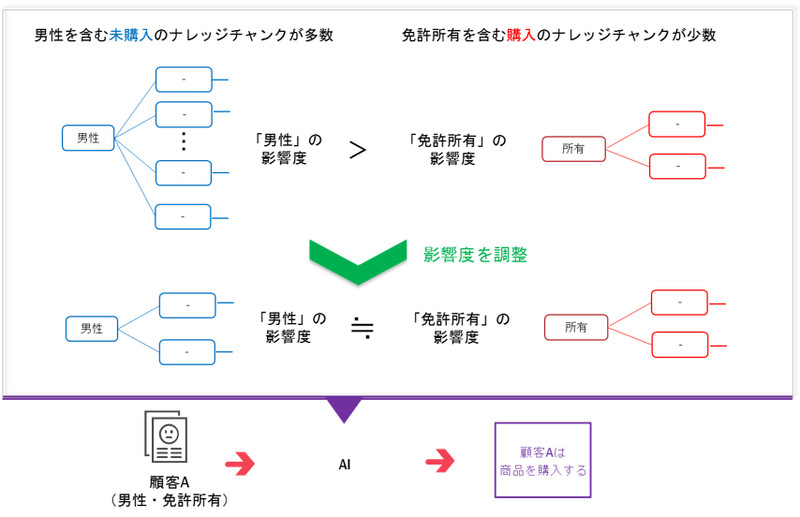
ナレッジチャンクを構成する項目が、ほかのナレッジチャンクを構成する項目と多く重複する場合は、ナレッジチャンクの影響度を制御して、高精度な判定が可能なモデル学習を実現する。
たとえば、「男性」を含むナレッジチャンクが多く、「免許保有」を含むナレッジチャンクが少ない場合、「男性」を含むナレッジチャンクの影響度を低く抑え、「免許保有」を含むナレッジチャンクの影響度を相対的に高くして学習する(図2)。データの重複や偏りの影響を抑えながら、正確に判定できるモデルを構築できるとしている。
富士通研究所はWide Learningを、米カリフォルニア大学アーバイン校が公開しているデータセット「UC Irvine Machine Learning Repository」の中から、マーケティングと医療領域のデータセットで検証した。その結果、正解データを当てる精度が10~20%ほど深層学習を上回り、サービスへの加入見込みが高い客を見逃す確率と、罹患患者を見逃す確率を20~50%ほど下げられたとしている。
具体的には、5000件のうち購入顧客データが約230件と、正解データが少ないデータを使って販促対象を決めたところ、深層学習では見込み顧客120人を販促対象から外したが、Wide Learningでは、その数を74人にまで減らせた。
今後は、不正利用や設備故障など発生頻度が低い事象を対象とした分析や、金融取引、医療診断など、判断理由を説明する必要がある業務での分析への活用を進め、2019年度の実用化を目指す。