- News
- 共通
業界特有の用語や文脈に対応するAIのための言語モデルの構築手法、NTTデータが開発
専門性の高い業界用語や言い回しに対応できるAI(人工知能)システムを実現するための言語モデルの構築手法をNTTデータが開発した。追加学習に必要な文章をインターネットから収集することで特定の業務領域に最適化した言語モデルを早期に構築する。2021年3月16日に発表した。
NTTデータが開発した「ドメイン特化BERT構築フレームワーク」(ドメイン特化BERT-FW)は、業務領域(ドメイン)特有の専門用語や文脈を理解するためのAI(人工知能)システムが必要とする言語モデルを構築するための手法。専門性の高い用語や言い回しを含む文書の認識精度を高めるのが目的だ。
新モデルの性能を、金融系の一種外務員資格試験の模擬試験に回答するAI(人工知能)システムに適用し、得点を比較したところ、440点満点に対し汎用モデルの「NTT版BERT」が280点、NTTデータが2020年7月に構築した「金融版BERTモデル」が308点だったのに対し、新モデルでは328点を獲得できたという。同試験の合格相当点数は308点(7割)である。
精度の向上を可能にしているのは、学習データの作成方法。処理対象にした業務文書から、一般的な言語モデルでは扱いが難しい文章を選別したうえで、専門用語を含む類似文章をインターネットから収集することで、特定の業務領域により特化した言語モデルを構築するための「ドメインコーパス」を作成する(図1)。
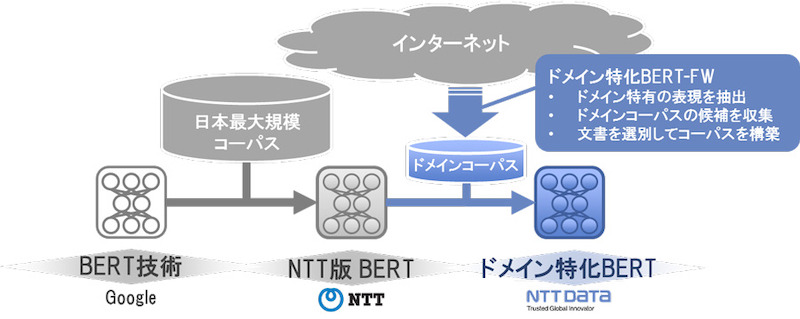
従来は、米Googleの汎用自然言語処理モデル「BERT」(Bidirectional Encoder Representations from Transformers)を基に、NTTグループが持つ独自のコーパスを元に学習してきた。
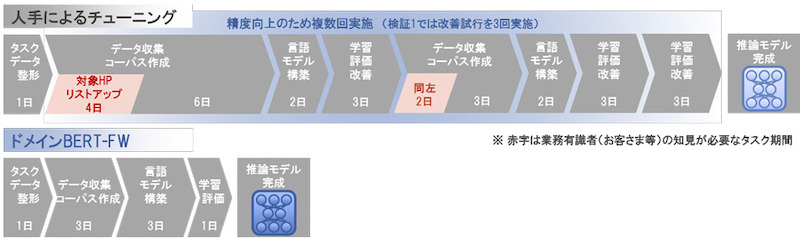
ドメインコーパスを作成することで、「業界」が意味する範囲を事前に定義するのが難しいという課題の解決を図っている。専門家がチューニングするよりも短期間で業界を問わず言語モデルを構築できるとしている。実際、上記の試験解答用モデルを構築するのに、金融版BERTモデルが29日を要したのに対し、新モデルは8日で構築できたとしている(図2)。副次効果として業務ノウハウを持つ有識者による作業も不要になった。
新しい言語モデルの適用例として、電子カルテの記載内容チェック、創薬に向けた論文や症例報告の活用、安全データシート(SDS)記載の危険度チェック、試薬の法規制確認やリスク評価、稟議(りんぎ)書の記載内容の確認、日報からのプロジェクトリスクの抽出、FAQ(よくある質問と回答)の回答自動引き当て、社内のマニュアルや技術文書の検索などを挙げる。
NTTデータは今後、共同検証に参加する企業や公共団体などを2021年4月から7月末まで募集し、2021年度中に5件の共同検証実施を目指す。