- News
- 共通
日本語らしい変換や話者識別ができる音声認識ソフトウェアの新版、NTTテクノクロスが発売
2021年12月17日
NTT研究所が開発した音声音響処理や自然言語処理などの機能を搭載した音声認識ソフトウェアの最新版をNTTテクノクロスが2021年11月19日に発売した。人間と同じような処理をすることで、より日本語らしいテキストへの変換や、複数の話者の識別などを可能にした。2021年11月12日に発表した。
NTTテクノクロスの「SpeechRec Server」は、NTT研究所の成果を活用した音声認識ソフトウェア。今回、NTTコンピュータ&データサイエンス研究所が開発したAI(人工知能)技術「MediaGnosis」を採用し、日本語の変換精度を高めた。音声認識に必要な処理をプロセス単位ではなく、「End-to-End」方式で一連のプロセスとして実施するのが特徴だ(図1)。
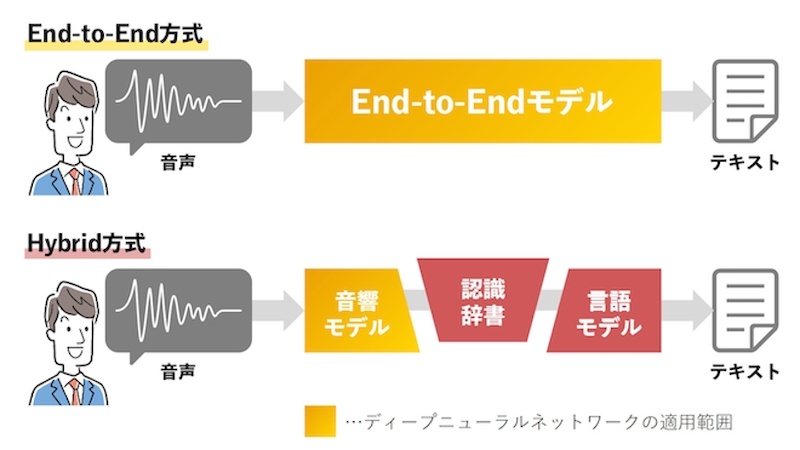
End-to-End方式とは、従来は一部の音声情報処理のみに適用していたディープニューラルネットワーク(DNN)をすべてのプロセスに適用し、音声データの入力からテキストの出力までを一連のプロセスとして処理するもの。システムの複雑化・高コスト化を避けられるほか、新たなニーズにもシステム構成を変えずに対応できるとしている。
最新版では、音声の認識精度を高めるとともに、相づちや「えー」「あのー」といったつなぎ言葉、「私なんかは」などの話し言葉特有の表現を認識し、意味を理解しやすいテキストに変換できるようにした。テキスト化した情報を内容ごとに分類した表示もできる。
複数の話者が話している音声データから、話者を識別する「話者ダイアリゼーション機能」も搭載した。声質や波形などの特徴から話者を識別する。話者を識別するために、個々の音声を事前登録したり話者ごとにマイクを用意したりする必要がなくなる。
NTTテクノクロスによれば、デジタルトランスフォーメーション(DX)の浸透や働き方改革により、官公庁やコンタクトセンターをはじめとする企業などにおいて、音声認識へのニーズが高まっている。