- News
- 製造
エッジやオンプレミスで動作する製造業特化の言語モデル、三菱電機が開発
製造業に特化しエッジデバイスでも動作する言語モデルを三菱電機が開発した。独自技術で軽量化を図り、メモリー容量や計算リソースになどに制約のあるエッジデバイスやオンプレミス環境でも動作する。2026年度中の製品化を予定する。2025年6月18日に発表した。
三菱電機が開発したのは、製造業に特化した生成AI(人工知能)システムの構築を可能にする言語モデル(図1)。独自技術で軽量化を図ることで、大規模言語モデル(LLM:Large Language Model)ではメモリー不足で実行が難しいエッジデバイスや、計算リソースに制約のあるオンプレミス環境での動作を可能にした。
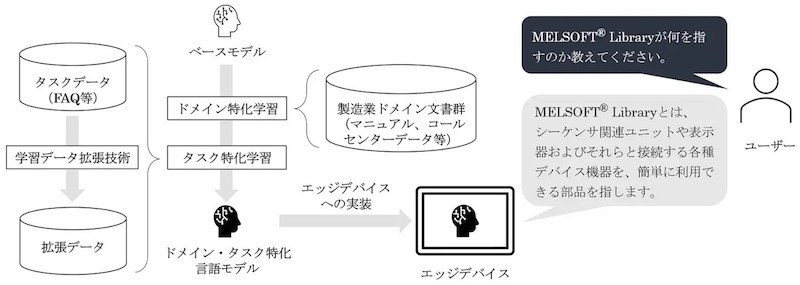
ユースケースには、スマートファクトリーやエッジロボティクス、エネルギー制御、コンタクトセンターなどを想定し、2026年度中の製品化を予定する。産業機器やロボットといったユースケースも検討し社内外での実証も進める考えだ。
軽量化に使用したのは「モデル圧縮技術」。モデルのパラメーターを、より少ないビット数で表現する量子化などにより、モデルの精度を保ちながらデータサイズを削減する。軽量化は生成AIシステムの運用コスト削減にもつながるという。
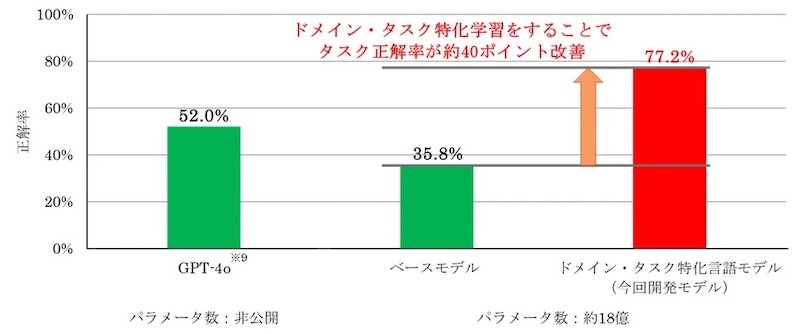
製造業向け言語モデルとしての精度としては、自社のFA(Factory Automation)製品に関する知識の正誤を問うタスクで評価したところ、正解率が77%だった。同タスクによる「GPT‑4o」(Open AI製)の評価では正解率は52%だった(図2)。
製造業に特化させるための学習では、国立情報学研究所 大規模言語モデル研究開発センターが運営する「LLM勉強会」が公開するモデルをベースに(1)ドメイン特化と(2)タスク特化の2つの学習を実行した。
ドメイン特化学習では、製造業の種々のユースケースに対応するため、FA事業のデータや、製品マニュアル、コンタクトセンターの応対履歴などの製造業特化のデータを使用する。いずれも三菱電機自身が保有するデータで、権利と倫理の面で問題がないとする。
タスク特化学習では、学習用データを生成する「データ拡張技術」を使って学習の効率を高めた。FAQ(良くある質問と答)などの用途別学習用データから「望ましい回答」と「望ましくない回答」のペアを疑似的に生成し学習に用いる。データ拡張技術は、利用者が保有する用途別データを用いる追加学習にも対応できるという。
開発にあたり三菱電機は、米AWS(Amazon Web Services)日本法人が提供する支援制度「AWSジャパン生成AI実用化推進プログラム」に参加し、コンピューティングリソースの調達や分散トレーニングの環境構築、アドバイザリーなどの支援を受けている。
三菱電機によれば、近年はLLMの使用が拡大する一方で、そのために必要な莫大な計算コストとエネルギーの削減が社会課題になりつつある。データプライバシーや機密情報管理の観点から、オンプレミス環境での生成AIの利用ニーズも高まっている。