- UseCase
- 製造
京セラ、生産性向上と業務革新に向けて全社共通のデータ基盤を刷新
2020年7月9日
京セラは、生産性の向上と業務革新を目的に、全社共通のデータ基盤を2020年5月に刷新した。社内に点在するデータを統合し、リアルタイムでの分析に利用する。2020年6月12日に発表した。
京セラは、各事業部門や工場IoT(Internet of Things:モノのインターネット)で収集しているデータを分析するための基盤を2020年5月に本番稼働させた(図1)。生産性の向上と業務革新を推進し、事業部間連携による新たなビジネスモデルの創出を目指す。
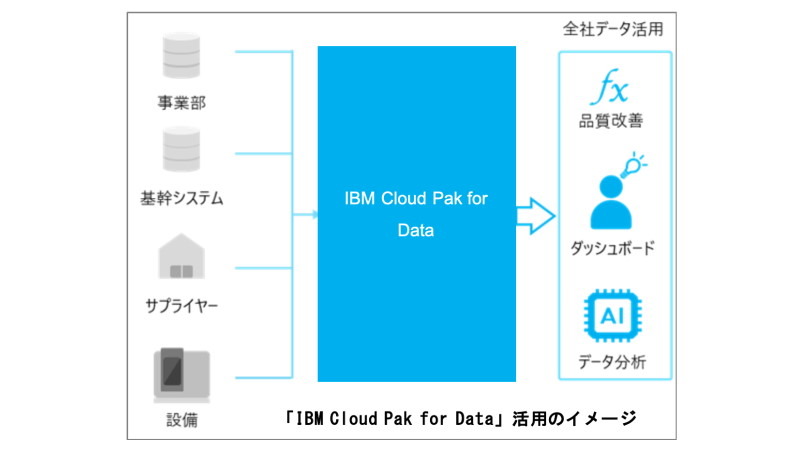
京セラは、工場などのデータを分析するための基盤を2017年10月から構築・利用してきた。今回刷新した新データ基盤では、生産データなど工場のシステムごとに蓄積されているさまざまなデータを統合し、工場内で日々発生する大量データをAI(人工知能)によってリアルタイムに分析する。全社共通基盤のため、シームレスなデータ分析ができると期待する。
併せて、データサイエンティストのデータ分析作業において、多くの工数を占めていたデータの収集から蓄積、理解、加工までのデータ準備の負荷低減を図り、分析作業により多くの時間を割けるようにした。
新データ基盤は、AIを使ったデータ分析のためクラウドサービス「IBM Cloud Pak for Data」(日本IBM製)を利用している。
| 企業/組織名 | 京セラ |
| 業種 | 製造 |
| 地域 | 京都市(本社) |
| 課題 | 社内に点在するデータを全社的に有効活用したいが、データ分析の前処理に時間が取られている |
| 解決の仕組み | 全社共通のデータ基盤に刷新し、全社横断でのデータの収集・編成・分析を可能にする |
| 推進母体/体制 | 京セラ、日本IBM |
| 活用しているデータ | 工場IoTで収集する生産データなど |
| 採用している製品/サービス/技術 | 「IBM Cloud Pak for Data」(日本IBM製) |
| 稼働時期 | 2020年5月 |