- Column
- 学校では学べないデジタル時代のデータ分析法
データの関係性パターンとしての「構造」と「空間」【第9回】
データの関係性に見られるパターンの1つが構造である(図1)。
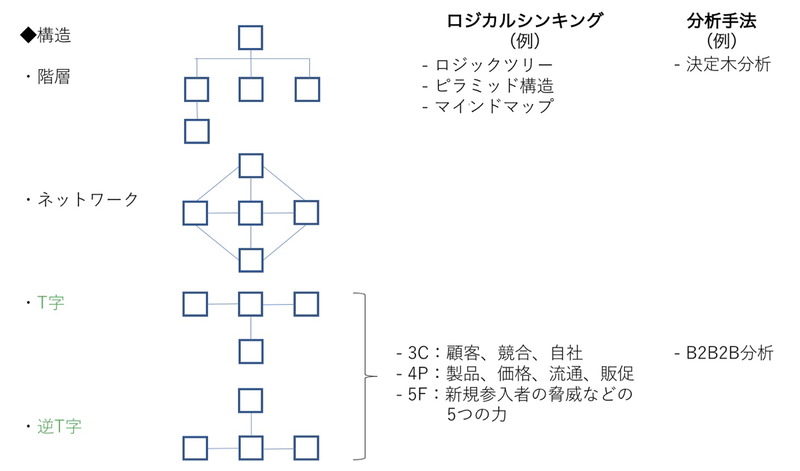
構造を表す手段の代表的なものが「階層」だ。だが階層だけでは、データ分析の実プロジェクトでは物足りない。大きく2つの課題に直面するためである。
課題点1:複雑なデータ構造への対応
第8回において「Trusted Data」を説明した際に指摘したように、階層化では、分析の過程でデータの対象が逆に大きくなっていく。たとえば、自動車部品というデータについて分析していくと、その上位部品あるいは下位部品へと対象は広がっていく。加えて、部品を製造するメーカー、その部品のバイヤーやサプライヤー、脅威となる競合会社や新規参入メーカー、さらに部品を置き換える代替品などにも対象は広がっていく。
分析対象である全体の、どの一部を取り出して拡大しても、似たような構造が出てくる。これを幾何学の世界では「自己相似」と呼ぶ。一部が全体と自己相似な構造を持っていて、まるでフラクタルのようである。
課題点2:“未知の未知”への対応
ビジネスの4大経営資源は「ヒト・モノ・カネ・データ」である。分析対象も同じく、これら4大要素を分析対象にしてきた。しかし、B2B2B(企業対企業対企業)の領域でのデータ分析では、今見えているデータの“先の先”、つまり未だ見えていないデータをつないでいかねばならない。
リスク管理の分野には「Unknown unknowns(未知の未知)」という言葉がある。何が分からないかが分からないという、一番悪い状況だ。せめて何が分らないかを理解する「Known unknowns(既知の未知)」にはしたい。
そのためには、「Any Data」「Trusted Data」「Open Data」「Alternative Data」など、一見関係がないと思われる複数のデータ群を紐付けする必要がある。B2B2B領域でUnknown unknownsから脱するには複数データ群の分析しかないのである。
階層構造では拡散するB2B2Bの構造に対応した独自フレームワーク
これら2つの課題点に対応しなければ、たとえばサプライチェーンマネジメントにおけるモノの流れを分析し、効率や効果を高めることはできない。そこで筆者は、ロジカルシンキングの考えをもとに、独自のフレームワークを考案した。「T字フレームワーク」と「逆T字フレームワーク」である。これらを使えば、部品のサプライチェーンという複数データ群の構造を分かりやすく可視化できる。
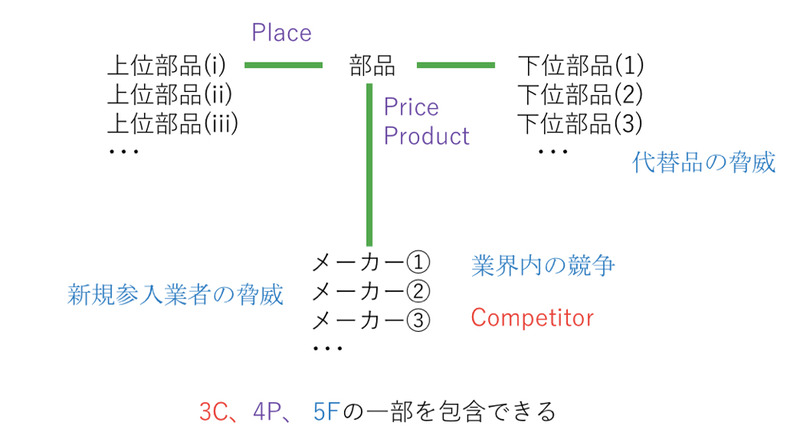
T字フレームワークは、「部品と部品」の関係を表現するものだ(図2)。ある部品の上位部品と下位部品といったB2B2Bの構造を、その部品を複数メーカーが製造する場合も表せる。
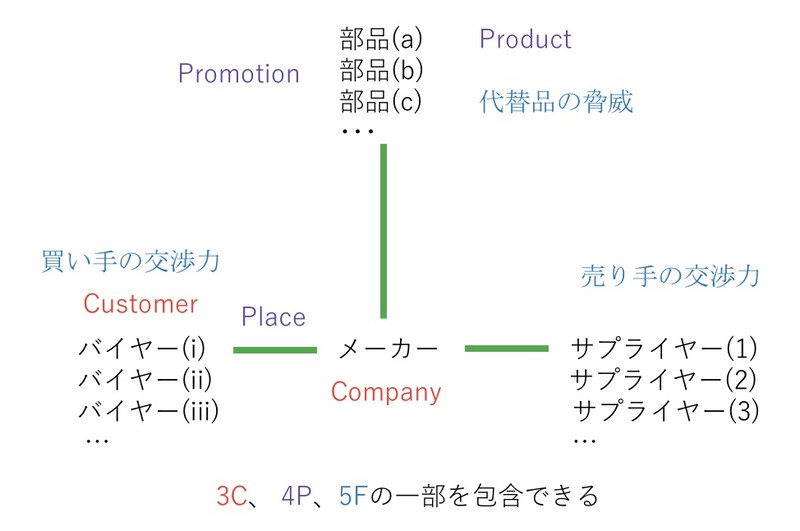
一方の逆T字フレームワークでは、「メーカーに対するバイヤーとサプライヤー」というB2B2B構造を表す(図3)。そのうえで、メーカーとメーカーの関係性を可視化し、メーカーが製造する複数の部品も表現できる。