- Column
- 学校では学べないデジタル時代のデータ分析法
分析では複数の手法の組み合わせが大切【第37回】
2020年8月31日

今回は、本連載『学校では学べないデジタル時代のデータ分析法』の総まとめとして、分析手法を改めて概観してみる。多数の分析手法があるが、分析において最も大切なことは、目的に応じて複数の手法を、どう組み合わせるかを見抜くことである。
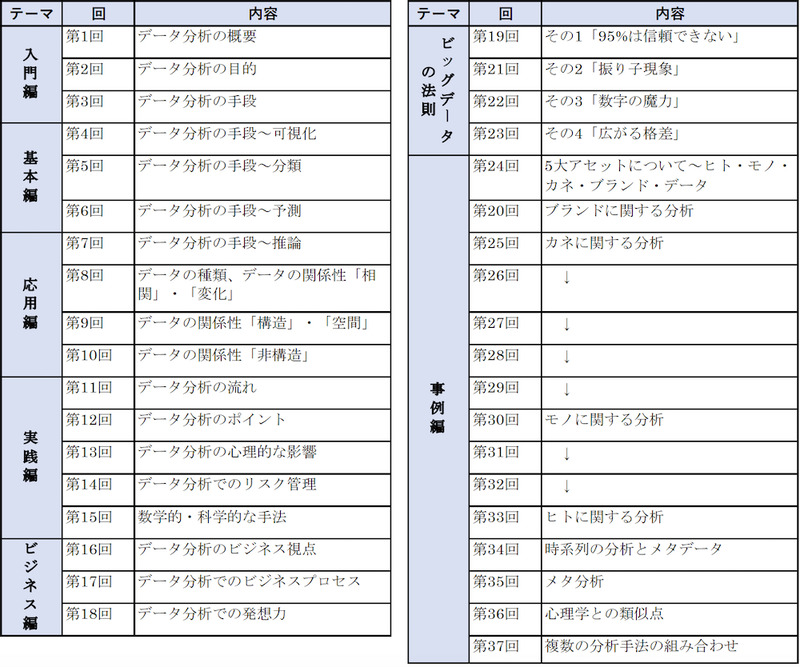
本連載の第1回から第37回までで紹介した内容をまとめたのが表1である。それぞれは入門編、基本編、応用編、実践編、ビジネス編、ビッグデータの法則、事例編の7つテーマからなっている。読者の興味やレベルに応じて各回を読みこんでいただきたい。
分析手法には利用頻度の高低がある
各回で繰り返して述べてきたように、分析の中身は幅広い。可視化、分類、予測、検定、推論、判別、検証の流れで進む。
たとえば、第5回で述べたように、分からないことを知るために、クラスター分析や主成分分析、因子分析などによって分類し、ある程度の当たりをつけ、クロス集計や決定木分析などで対象を絞り込んでいく。
その際、データの差がバラつきによって偶然生じたものかどうか判断するためにt検定を実施したり、データ量が大きければz検定を実施したりする。
次に、重回帰分析やロジスティック回帰分析で影響度を測る。これにより方向性が見えてきたら判別分析で先読みをする。最後に、効果を見るために検証する。これが分析の基本である。
分析手法としてはこれまで、表2に挙げたものを紹介してきた。
| 分析の目的 | 分析手法 |
|---|---|
| 分類 | クラスター分析、主成分分析、因子分析 |
| 絞り込み | クロス集計、決定木分析 |
| 関係の強弱を知る | 相関分析 |
| 影響度を測る | ロジスティック回帰分析、(重)回帰分析 |
| 先読み | 判別分析、MT法 |
| 検証 | ランダム化比較試験(A/Bテスト)、コホート研究、ケースコントロール法 |
| 推論 | ベイズ推定 |
| 空間把握 | トポロジカルデータ解析、スパースモデリング |
| 非構造化 | テキストマイニング(形態素解析、アソシエーション分析) |
これら分析手法に関する膨大な文書をテキストマイニングすると、各手法の利用頻度があぶり出される。筆者が分析した経験上も同じような傾向だ。利用頻度が高い手法は、表3のようになる。
| 順位 | 手法 |
|---|---|
| 1 | クロス集計 |
| 2 | クラスター分析 |
| 3 | 回帰分析 |
| 4 | 決定木分析 |
| 5 | 相関分析 |
| 6 | ロジスティック回帰分析 |
| 7 | 因子分析 |
| 8 | アソシエーション分析 |
| 9 | 判別分析 |
| 10 | 主成分分析 |