- Column
- データ活用力をDataOpsで高める
機械学習モデルを使ったデータの業務への活用法【第3回】

データ分析で最も注目されているのが、AI(人工知能)を支える技術である機械学習(ML:Machine Learning)を使った“未知の事象”の推論だろう。今回は、この機械学習モデルを例に、データ分析の結果を業務活用につなげるまでのプロセスについて、社内における、それぞれの関係者(ステークホルダー)の連携について解説する。
DataOpsに基づくデータ活用には、さまざまな形態がある。定型的な分析レポート生成、経営指標を解析するBI(Business Intelligence)ダッシュボード、機械学習(ML:Machine Learning)を用いた推論、最適化による計画立案などだ。なかでも近年注目されているのが、機械学習を使ったシステムだ。
機械学習では、学習したデータのパターンから未知の事象を推論する。これまでなら、考えられなかった強力な使い方ができるのが最大の魅力だ。一方で、現場に適用するためのハードルが高いという課題がある。
以下では、機械学習モデルを使ったデータ分析プロジェクトを例に、業務活用につなげるまでのプロセスにおける、各関係者(ステークホルダー)が、どう連携すべきかを解説する。ステークホルダーは、データを供給する現場の「業務担当者」、データを活用する「分析担当者」、そのための基盤を用意する「IT担当者」である。
試行錯誤のアプローチを採るCRISP-DMフレームワーク
データ活用プロジェクトを進める上で参考になるフレームワークの1つに「CRISP-DM(CRoss-Industry Standard Process for Data Mining)」がある。CRISP-DMフレームワークでは、データ活用のプロセスを(1)ビジネスの理解、(2)データの理解、(3)データの準備、(4)モデル作成、(5)評価、(6)展開との6つのフェーズに分けて定義する。
データ活用プロジェクトは、5ステップのサブプロジェクトに分割し段階的に進めていく(図1)さらに、“試行錯誤的”なアプローチを採っており、上記の6フェーズを順に実行するだけでなく、場合によっては後戻りしてやり直す。
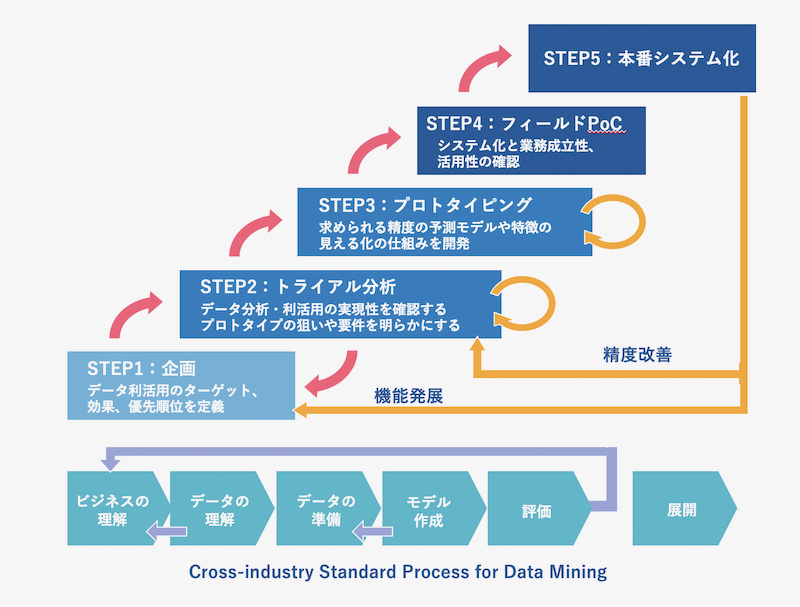
図1に示したサブプロジェクトはあくまで目安だ。実際には、企画とトライアル分析が混在するなど、さまざまなパターンがあり得る。重要なのは、各ステップをなるべく高速に回しながら、あらかじめ設定したチェックポイントにおいて「先に進む」か「やり直す」かを判断し、不確定要素を早めに、かつ確実につぶしていくことだ。
立ち上げ時からの現場との密接な協働が不可欠
CRISP-DMフレームワークに基づくデータ活用プロジェクトを進めていく上で、業務・分析・ITのそれぞれの担当者は、どのように関われば良いのだろうか。
ありがちな間違いは、プロジェクト全体をデータ分析者に丸投げしてしまうパターンだ。特に、企画やトライアル分析などの初期段階を、業務側のメンバーが深く関わらずに進行させるとプロジェクトの失敗につながりやすい。
その原因は、成果を評価するための指標であるKPI(Key Performance Indicator:重要業績評価指標)の設計が不十分で、現場の感覚とはギャップがある状態に陥りかねないことにある。実行結果の評価が納得されず現場に受け入れられない危険性が高まる。
業務側の現場担当者をプロジェクトに主体的に関わってもらうには、データ活用のメリットについて早期に理解を得、自ら率先して取り組もうという気持ちを醸成することが必要だ。そのためには、企業の人材育成の観点からも、基礎的なデータリテラシーを組織全体に定着させるための教育活動が重要になる。
この段階における分析担当者の役割は、データの視点から業務を読み解いて仮説を示し、業務側の洞察力を高めて本質的な課題を一緒に導き出すことだ。そのためには、分析側も業務側に深く踏み込んでいくことが大切である。
特に分析の側面でベンダーやコンサルタントなど外部の力を借りる場合は、業務側との距離が遠くならないよう一層の配慮が必要になる。