- News
- サービス
京セラの工場IoTを支えるデータ基盤、アプリ開発のDevOpsとAI活用のMLOpsをIBMクラウドで両立
AIを活用する向けた「AIラダー」が示す4つのステップ
「DevOpsだけで、アジャイルな経営ができると思ってはいけない。状況の変化に迅速かつ柔軟に対応するには、データやAIを活用して、自動化・最適化を図らなければならない。アプリケーションから出たデータを分析し、その結果を返すループの構築が必要だ」と正木氏は指摘する。
特に、図2の右側のサイクルであるAI活用の部分で「多くの企業が停滞する」(正木氏)という。「AI活用は段階的に進める必要があり、ハシゴのように一段ずつ登っていかなければいけない。これをIBMは『AIラダー』と呼んでいる」(同)
AIラダーは、データの価値を引き出しAIを活用するために必要なアプローチと、そのアーキテクチャーを定義したものだ。(1)「コレクト」、(2)「オーガナイズ」、(3)「アナライズ」、(4)「インフューズ」の4つのステップを上っていく(図3)。
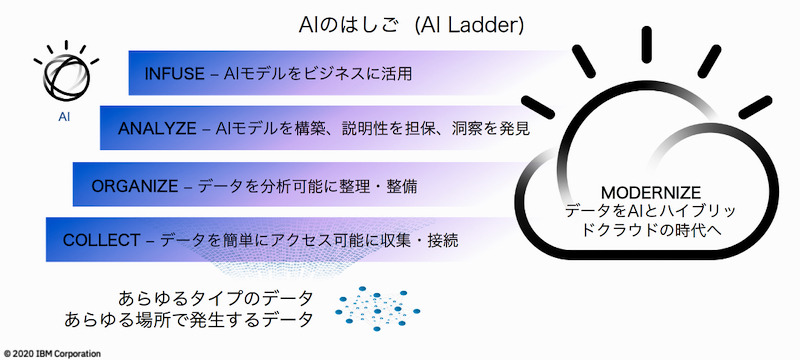
コレクトでは、企業内にある種々のデータにアクセスし、活用できるようにする。オーガナイズは、集めたデータを全社で使えるよう、クレンジングやカタログ化などを実施する段階だ。これができていないと、データを全社のさまざまな部署で活用できない。
アナライズでは、オーガナイズで整理されたデータを基にAIモデルを作る。そしてようやく、分析結果を実際にビジネスに入れ込んでいくインフューズの段階を迎える。
しかし、企業がAIラダーを順調に上っていくのは難しい。正木氏によれば、「バリューの高いアナライズとインフューズに時間を使うべきデータサイエンティストが、業務の約8割をコレクトとオーガナイズのために費やしている」
この問題を解決するには、データの取り込みと前処理を自動化できるデータ基盤が必要になる。京セラが採用したIBM Cloud Pak for Dataは、企業内に分散しているデータを1カ所に集め、分析に使えるレベルにまでデータの品質を高める機能をもっているという。
各社の共通課題をコンポーネントとして用意
一方、AIによる分析結果を利用する業務アプリケーションには、「多くの企業が直面する共通の課題がある」と、日本IBM クラウド&コグニティブ・ソフトウェア事業本部 Data and AI 事業部 テクニカルセールス部長の田中 孝 氏が明かす(写真2)。
共通の業務課題に対しては、「あらかじめ開発済みのコンポーネントを提供する。たとえば、カスタマーを担当するオペレーター支援、経営企画部門が担当する事業計画の策定と業績予測などだ。金融系などで要望の多い、顧客企業のリスク管理といったツールを用意する」(田中氏)
2020年6月に提供を開始した最新バージョンの「Cloud Pak for Data v3.0」では、コンポーネントの拡張と、各コンポーネントをプラットフォーム上で一貫性して扱うためのユーザーインタフェースを改善した。
Cloud Pak for Dataは、IBMのData and AI部門の中核商品だ。BMがこれまでに構築・蓄積してきた業務アプアケーションが今後も、このデータプラットフォーム上に統合されることになりそうだ。