- News
- サービス
京セラの工場IoTを支えるデータ基盤、アプリ開発のDevOpsとAI活用のMLOpsをIBMクラウドで両立
京セラが生産性を高めるため、IoT(Internet of Things:モノのインターネット)データを活用するためのデータ基盤を刷新し2020年5月に本番稼働させた。同基盤の導入を支援した日本IBMが、2020年6月15日に開いた記者会見で、京セラの取り組みや、IBMが考えるデータ活用について説明した。
データ活用に取り組む企業が増えるなかで、日々増大するデータが社内に分散し、その扱いに悩んでいるケースが少なくない。データは、有効に活用できれば“宝の山”だが、その管理や運用には試行錯誤が続く。
そうした中、「新型コロナウイルス感染症(COVID-19)の拡大が企業経営者の気持ちに変化を与えている」と、日本IBMクラウド&コグニティブ・ソフトウェア事業本部 Data and AI 事業部 理事の正木 大輔 氏は語る(写真1)。
「多くの経営者は、この先もコロナに匹敵する事態が起こると考えるようになった。そして、それをどうやって乗り越え企業を成長させるのかを、これまで以上に考えている」(正木氏)
今後を考えるうえでカギになるのが、デジタルを活用した俊敏な(アジャイル)経営だ。正木氏は、「これまでのデジタル変革は消費者向けのサービスがリードし、企業の取り組みは実験段階のところが多かった。それが、いわばデジタル活用の“第二章”というべき、企業が本番環境でデジタルを活用する時代が訪れた」とみる。
そのために「必ず必要になるのが、データを収集し分析するデータ基盤(プラットフォーム)だ」と正木氏はいう。
同じ課題に直面していた企業の1社として京セラを挙げる。生産性向上を目的に、日々生成される膨大なIoT(Internet of Things:モノのインターネット)データを取得し、AI(人工知能)でリアルタイムに分析してきたが、データを活用し切れていなかったという。
同社は実は、データ基盤を2017年に導入している。各事業所が持つシステムに点在していた業務データや、工場内のIoTデータなどを集約し分析することで、生産性の向上や業務革新を図るためだ。しかし、その基盤の運用してみると、データサイエンティストが大量のデータを分析のためにデータを整備する作業負荷が大きいことがわかってきた(図1)。
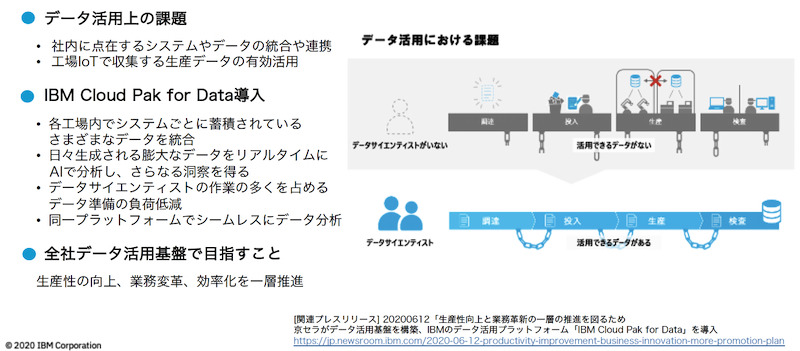
この問題を解決するため京セラは2020年5月、データ基盤を刷新した。採用したのは、IBMのデータ活用基盤「IBM Cloud Pak for Data」である。旧基盤と新基盤では何が違うのか。
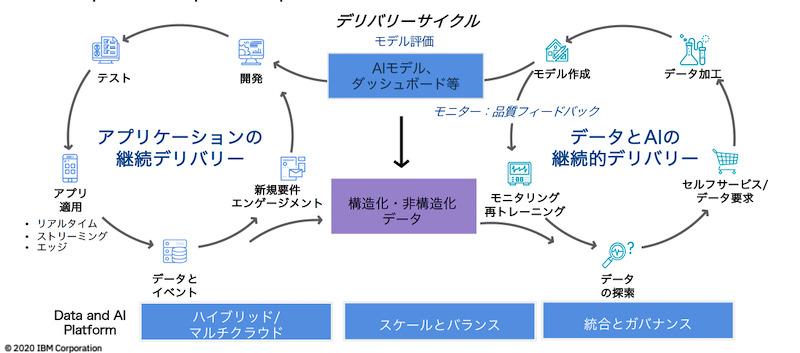
両者の違いについてIBMは、「企業が変化に対応するデータ活用を実現するためには、アプリケーションの提供サイクルとAIによるデータ分析サイクルの2つを継続的につなぐ必要がある」(正木氏)と説明する。
アプリケーションの提供サイクルとは、ビジネスアプリケーションの開発からテスト、運用までのプロセスを高速に回転させること。いわゆる「DevOps(開発と運用の融合)」と呼ばれる領域だ。
一方のAIによるデータ分析サイクルは、アプリケーションが生成するデータを取り込み、そのデータを加工・学習してモデルを作成し、再びアプリケーションに返すプロセスだ。これは「DataOps」や「ML(機械学習)Ops」と呼ばれている(図2)。