- Column
- 学校では学べないデジタル時代のデータ分析法
データに潜む関連性を見いだし将来を予測する【第6回】
手順4:予測して先を読む
「判別分析」の場合、多くのサンプルデータから推論モデルを構築する(図4)。文字どおり、このモデルによって判別を下す。商品購入者の分析では、年齢・年収・扶養者の数・職業・性別・趣味などの要因から推論モデルを作れば、新たに入力されたデータを判定し、ヘビーユーザーかどうかを判別できる。米Googleの猫を判別する画像認識の場合、新たに入れたデータを判別し、「猫である」「猫ではない」と分けていく。このようにAI(人工知能)を絡ませていくと機械学習になっていく。
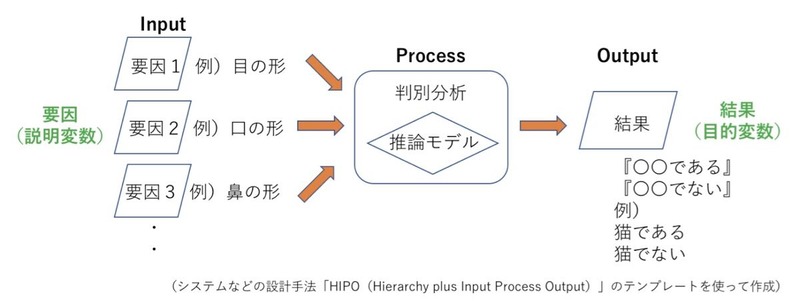
判別分析と比較される手法に「MT法」がある。たとえば、ある疾病になる恐れがあるかどうかを予測する。判別分析では、その疾病でない人々は似通っているとみる。同様に、その疾病にかかった人々も似通っているとみなす。それがMT法では、疾病でない人々は似通っているとする点は同じだが、その疾病にかかった人々は同集団とみなさず"十人十色"という前提に立つ。
なお、今回述べた、相関分析、重回帰分析、判別分析、ロジスティック回帰分析、MT法も多変量解析である。多変量解析は、分類から予測まで幅広く使える。
手順5:効果を検証する
分析は地味で地道な作業である。分からないことを知るために、クラスター分析、主成分分析、因子分析等によって分類して、ある程度の"当たり"をつけ、対象を絞り込んでいく。次に重回帰分析やロジスティック回帰分析で"影響度"を測る。これにより方向性が見えてきたら判別分析で先読みをする。最後に、効果を見るために検証する。
検証によく使われるのが、第2回で述べたランダム化比較試験の考えを礎にした「A/Bテスト」である。分析の結果、A案とB案の2つの案が出たとする。2つのグループに無作為にA案とB案を割り当て、それぞれのグループで検証した後に効果がより大きかった案を採用する。たとえば、商品の価格を税抜き、税込みいずれのパターンで表示するのが良いかをA/Bテストで検証すると、「税込み表示だと売り上げは平均8%低い」という実験結果が得られたという報告もある。
経済学は実験が難しい学問である。だがそれも、A/Bテストに代表されるランダム化比較試験によって検証されるようになった。A/Bテストは特にネットの世界で頻繁に利用されている。2008年の米大統領選では、オバマ候補への寄付金やボランティアの増加に、このA/Bテストが貢献している。また米国のクレジットカード会社は、1年間に3万件近いA/Bテストを実施している。勘に頼るよりも、データ分析に賢明に取り組むことで、ビジネスや選挙の戦略を立てているわけだ。
現場におけるデータ分析は、可視化・分類・予測・検証の作業の繰り返しが基本である。次回は、主観的な分析方法である「ベイズ推定」について例題を解きながら具体的に述べたい。
入江 宏志(いりえ・ひろし)
DACコンサルティング 代表、コンサルタント。データ分析から、クラウド、ビッグデータ、オープンデータ、GRC、次世代情報システムやデータセンター、人工知能など幅広い領域を対象に、新ビジネスモデル、アプリケーション、ITインフラ、データの4つの観点からコンサルティング活動に携わる。34年間のIT業界の経験として、第4世代言語の開発者を経て、IBM、Oracle、Dimension Data、Protivitiで首尾一貫して最新技術エリアを担当。2017年にデータ分析やコンサルテーションを手がけるDAC(Data, Analytics and Competitive Intelligence)コンサルティングを立ち上げた。
ヒト・モノ・カネに関するデータ分析を手がけ、退職者傾向分析、金融機関での商流分析、部品可視化、ヘルスケアに関する分析、サービスデザイン思考などの実績がある。国家予算などオープンデータを活用したビジネスも開発・推進する。海外を含めたIT新潮流に関する市場分析やデータ分析ノウハウに関した人材育成にも携わっている。