- Column
- 学校では学べないデジタル時代のデータ分析法
データ分析の王道としての順問題と逆問題を理解する【第11回】
データ分析においては、対象が(1)試行錯誤しながら結果を探索していく「順問題」なのか、(2)結果は経験値で分かっている中で原因を可視化する「逆問題」なのかを判断することが重要である。ITの知識が、かなり高い人でも、両者の違いを混濁されているケースが多々ある。これは分析の根幹なので、両者の違いを説明しておこう。
順問題とは、原因から結果を求める問題である(図1)。 “構造”から“機能”を発見する。確率が、この領域に入る。基礎研究や基礎医学も順問題である。たとえば、土中から新しい細菌を探し出し、その細菌を使って新たな薬を作るというやり方が相当する。

順問題が成功するかどうかは、次の3点を準備できるかどうかにかかっている。
(1)データ(大量データ、オリジナルデータ)
(2)アルゴリズム
(3)推論モデル
順問題の流れを図式化したのが図2だ。データを収集したら、分析に取りかかる前に、余分なデータを排除し綺麗にするのが王道である。これを「クレンジング」という。クレンジングの結果が、ロジカルシンキングで、ひんぱんに使われる「MECE(ミーシー:Mutually Exclusive and Collectively Exhaustive)」で、“漏れなくダブりなく”という状態だ。
ただし、綺麗にクレンジングしないほうが良いこともある。たとえば恐竜の骨の発掘では、こんなことがあったという。土に埋まっている恐竜の骨を発見したので、その場で綺麗にし、骨だけを持ち帰った。ところが現場に捨てたものの中に重要な資料が含まれていた。堆積物と思って削り取ったものが、実は内臓の化石だったのだ。
筆者自身、国家予算という生データを分析した際、単純にクレンジングするだけではデータが物語る意味を見失ってしまうことに気付かされたことがある。生データを見る際には、なぜ重複があるのか、なぜ漏れがあるのかを考えなければならない。重複や漏れ自体に深い意味があるからだ。王道から外れる勇気も時には必要である。
推論の結果が知識になり、知恵へと変わっていく
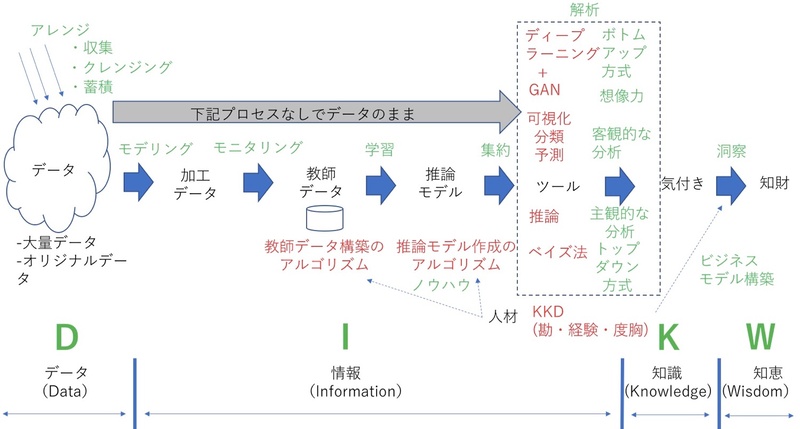
クレンジングするかどうかを判断し、それが終了すれば、データを蓄積する。ある程度の大量データが必要だが、他では入手できないオリジナルデータを用意することが望ましい。
複数のデータ群を紐づけし、複数データ間に関係性を付けていく。これがモデリングである。この段階では、新たな列の追加も大切になる。モデリングの結果できるのが加工されたデータ、すなわち「情報」である。
生データでも、うまく可視化・分類できれば予測が可能になる。だが、その結果は、あくまでも事実に過ぎない。真実は推論しなくては出てこない。そこで、生データから学習しながら、規則を見つけ出し「教師データ」を構築し、そこから推論モデルを生み出す。その際の考え方が「アルゴリズム」である。この学習・推論モデルの構築段階を経れば、真実にたどり着ける。
予測やベイズ推定などを使った推論の結果が“気付き”であり「知識」になる。それを基に経験を持った人材がビジネス視点で洞察を行えば「知恵」になっていく。すなわち、データ(Data) → 情報(Information) → 知識(Knowledge) → 知恵(Wisdom)の流れだ。この頭文字を取って「DIKW」と呼ぶ。
なお、複数の「情報」を集約して束にすれば、人手による分析には、あまりにも手間がかかりすぎる。そこでツールの登場となる。しかし、順問題において、何の考慮もせずに、いきなりツールに依存しても真実は浮かび上がってこない。これが、失敗するケースのほとんどであり、多くの分析結果が期待値を下回ってしまう。