- Column
- 学校では学べないデジタル時代のデータ分析法
データ分析には数学的・科学的手法を生かすセンスが不可欠【第15回】
センス2:手元にないデータを予測する
トポロジー分析のように、莫大なデータから未知の法則を探し出すことは大切だ。だが、すべてのデータを取得して分析するには、時間とコストがかかる。実際、膨大な観測データは、そのままでは解明させるまでに多大な時間を要する。
スパースモデリング
そのため、まばらにデータを取る方法の1つとして、スパースモデリング(Sparse Modeling)がある。「スパース」は「まだら」という意味だ。少ないデータから真実を見いだす過程で広く使われている。応用例には、MRI(磁気共鳴画像装置)や、EV(電気自動車)の素材開発、津波予測、テストのカンニング検出、脳の解明、ブラックホールの形の推定などがある。
スパースモデリングでは、複雑なデータをまばらにすることで情報に変換し、それをグラフ化し、形・文字列・数式などとして解いていく(図2)。ここでも、“DIKW”、すなわちデータ(Data)を、情報(Information)、知識(Knowledge、グラフ化)、知恵(Wisdom、形・文字列・数式など)へと変わるプロセスになる。
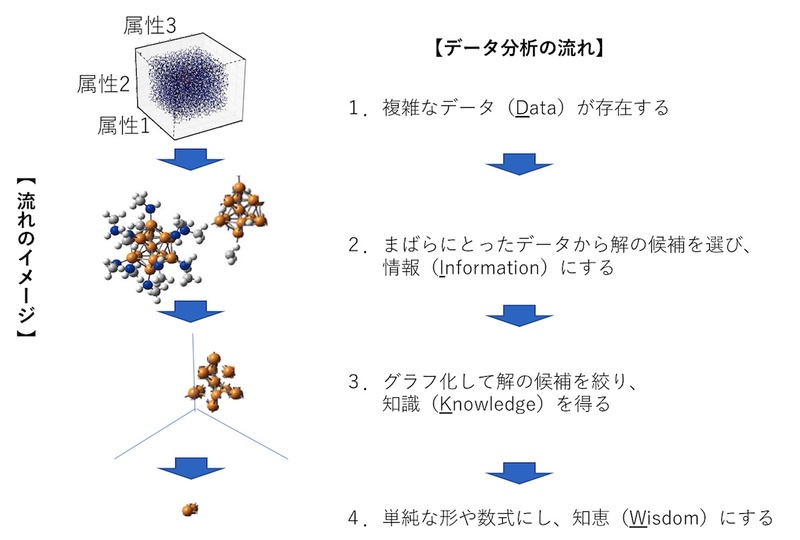
スパースモデリングは数式で表される。式の詳細説明自体は別の機会に譲るが、大切なポイントは、間引きした観測データから解の候補を選ぶことだ。しかし、解を1つには絞り切れないので、スパース性を利用し復元しながら解の候補を絞っていく。このプロセスを繰り返すことで最適な解にたどり着く。
すでにビッグデータのすべてを分析する時代ではない。まばらなデータを基に足りない部分を予測して分析する時代である。言い換えると、手元にはないデータは、実在しそうなデータとして“作る”時代に突入していると言えよう。そこでは、論理学や言語学、気象学などを含めた総合的なアプローチが必要になる。
フェルミ推定
実際、調査すら難しい課題は少なくない。たとえば、「読者が今いる場所から見えているビルには何人が入っているだろうか?」といった問題は、とらえどころがないし、実態調査も難しい。
そのため、いくつかの手掛かりから論理的に推論し、短い時間の“閃き”で解を求める必要がある。これがフェルミ推定だ。 実際にデータを取得するのではなく、頭の中で仮説を立てる。データも自らの経験値と推論で用意する。
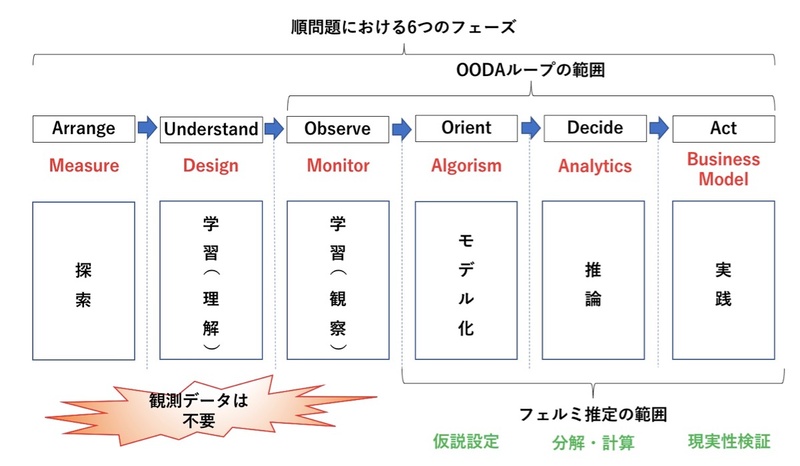
フェルミ推定は、実際の把握が難しい数量を類推する順問題である(第12回参照)。ただ、生データを取得しないので、順問題のおける6つフェーズのうち、最初の3つは不要になる(図3)。まずモデル化し、分解することで計算をしやすくする。前述のビル内にいる人の数の例では、オフィス棟、住宅棟、商業棟に分解し、それぞれについて人数を求めるという推論になる。すでに統計データがあれば実践段階で現実性を検証する。
なお、AI(人工知能)がデータを自ら作るという話は、第11回のGAN(敵対的生成ネットワーク:Generative Adversarial Networks)で触れたが、関連して比較するとよい。GANは、敵対するAIをだます中で実在しそうなデータを作り出し、成長しながら想像力を獲得していく。