- Column
- データ活用力をDataOpsで高める
データ活用を企業に定着させるシナリオ【第5回】
ステージ1 → 2:小さな成功体験を創出する
データ活用に取り組んでいない企業がデータ活用に取り組み始めるのが、ステージ1からステージ2に進むステップである。
データ活用に取り組み始めるタイミングでは、データが先か、分析が先かについて悩むことが少なくない。データ活用力が十分に醸成されていない段階は、活用可能な高品質のデータがそもそもなく、品質の定義も決められないケースが多いためだ。データ要求を整理したとしても、データの品質整備や新規取得コストに対して、データ分析の効果を説明しきれないケースもあるだろう。
この場合、まずは収集可能なデータでPoC(Proof of Concept:概念検証)を実施し、その結果をフィードバックする。原因分析と改善の仮説をデータから説明することで、分析によって得られる効果とデータ品質の関係を理解しやすくする。高品質なデータの取得に向けた動機付けをし、データ分析の成功確度を高める。
この段階では、小さな成功体験を得るために実効性(ビジネス価値)の高いデータ活用テーマを企画し、分析プロセスを効率的に推進することが重要である。
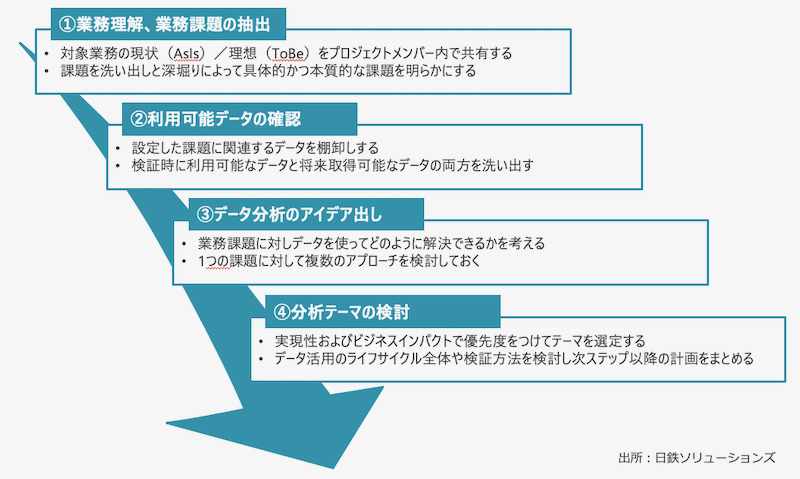
そのためのポイントは、データ活用プロジェクトの立ち上げだ。第3回でデータ活用プロジェクトの「STEP1:企画」として紹介したように、データを活用したい業務部門のメンバーだけでなく、外部コンサルタントやデータ分析の専門家、データ発生元のシステムを管理するIT部門も交え、ワークショップ形式でプロセスを進める(図3)。
ステージ2 → 3:取り組み範囲の拡大と分析の効率化
データ活用に関する理解が企業内で進むと、様々な新しい要求がユーザーから出てくるようになる。これがステージ3の「組織的な強化」に進む段階である。
利用データへの要求も増えるタイミングであり、データ提供とデータ分析の両面での効率化が求められる。データレイクやデータウェアハウス、データ分析環境(機械学習モデルの開発環境)など、取り組み規模の拡大に向けてIT基盤を整備するための投資も大きくなるだろう。
増大する投資に見合う効果を得るには、環境の準備や利用ルールの提供だけにとどまらず、ユーザーの活動を活性化するための施策を打ち、データ活用をサポートしていくことが肝要である。
例えば、ユーザー同士のコミュニケーション活性、人材育成支援、セルフサービス化の推進などの取り組みを実施する。これらを実施しないと、仕組みの利用とルールの遵守が、活動に対する制約として作用してしまい、徐々に使われなくなってしまう恐れがある。
ユーザー活動を活性化した結果として、プロジェクトの数や規模が拡大していくと、機械学習モデルの構築、業務利用までの一連のプロセス効率化が必要になる。第3回で紹介した、データ加工・モデリング・検証・本番適用の自動化によりデータ分析や機械学習モデルの開発負荷を下げる取り組みが生きてくるだろう。
データ分析は属人的な作業になることが多く、時間が経つと担当者本人でも分析過程を忘れてしまいがちだ。もし分析担当者が異動になり、次の担当者は分析をゼロからやり直さなければならない事態も考えられる。
こうした事態を避けるためにも、作業の自動化やトレーサビリティを管理する仕組みを備えることは、過去の分析資産を再利用可能とし、全体プロセスの効率化に寄与するだろう。
ステージ3 → 4:拡大・成長に向けた改善サイクルを確立する
データ分析活動が実際の現場で利用されビジネス価値の向上につながり始めると、拡大・成長に向けた改善サイクルを確立するステージ4へ移行するタイミングになる。
第3回で紹介したプロセスの自動化整備と併せて、第4回で紹介したモデルを継続的に改善するプロセスを実施し、データ分析の維持と改善を図ることが重要である。モデルの改善に向けて、ユーザー側やデータ分析者からは新たなデータの利用やデータ品質の改善要求が発生することが多い。
改善サイクルをうまく回すには、学習データを最新化した機械学習の再実行だけでなく、第2回で紹介したデータを収集して品質を継続的に高める「データマネジメント」のプロセスも同時に実行しなければならない。
ともすると業務システムやデータ基盤を管理するIT部門任せになり、業務やデータ活用プロセスと分離されがちだ。機械学習による分析と高品質データの継続的な運用を両輪で推進できるように留意して、全体のプロセスを整備する必要がある。
データマネジメントのプロセスでは、データ利用ポリシーやルール作りに加えて、データ利用者からのフィードバックを基にした追加データの取得、蓄積データへの説明の付与、データのクレンジング、特定のデータを抜き出したデータマートの構築といった作業を実施する。これらにより、データ品質を継続的に高め、ユーザーへのデータ提供を効率化するためのサイクルやプロセスを確立する。
このとき、データマネジメントの課題をITシステムで解決しようとするケースをよく目にする。だが実際には、データマネジメントのプロセス自体の整備や組織設計に課題が存在するケースが多い。データマネジメントの領域は広く、それに含まれる要素も奥深い。それだけに、すべてを網羅的に整備しようとすると実現性がなくなってしまうケースがよくあるので注意したい。
データマネジメントは目的ではなく、多様で大量なデータから利用者が高品質のデータを適正な手段で素早く入手できるようにするための手段である。その基本を押さえ、実現性や効果を検証しつつ段階的に実現を目指すことが重要だ。
企業のデータ活用につなげてほしい
第1回で述べたように、DataOpsは「データ活用のライフサイクルを確立して回しながら、事業への貢献度とその速度を持続的に高めていく」という目的のもとで推進する取り組みである。
そこには、ツールの準備や仕組みの構築にとどまらず、全体プロセスの推進と、そのための教育、企業風土・文化の醸成を含めたデータ活用力の向上が不可欠だ。「こうすればDataOpsが実現できる」という『銀の弾丸』のような解は存在しない。本連載で紹介したDataOpsの考え方や、データ活用ステージ、取り組みのステップやポイントが、データ活用の一助になれば幸いである。

瀧本 秀典(たきもと・ひでのり)
日鉄ソリューションズ (NSSOL) DX推進&ソリューション企画・コンサルティングセンター データ活用グループリーダー 兼 技術本部 システム研究開発センター インテリジェンス研究部 統括研究員。2000年 新日鉄情報通信システム(現・日鉄ソリューションズ)入社後、基幹系・情報系を併せて多数のシステム基盤アーキテクチャリングを担当。データ活用基盤、分析/AIに関する各種研究開発の推進を経て、現在はコンサルティング含め、企業のデータ活用事業支援を中心に活動している。