- Column
- DXの核をなすデータの価値を最大限に引き出す
データ活用サイクル・ステップ1:収集段階の取り組みと留意点【第2回】

前回は、“経験と勘”だけに頼らないデータ活用に必要な“収集・蓄積・活用のサイクル”について説明しました。今回は同サイクルの第1ステップである「データ収集」について説明します。目標設定に基づく戦略的アプローチやデータの信頼性の確保などがポイントになります。
データ活用においては、目的に応じた目標を設定し、仮説を立てて進めないと行き詰まってしまいます。その目的により必要なデータが異なります。仮設立案の段階でデータが十分にそろっていることは稀であり、十分な要件を満たすデータをそろえられないと目標を達成できなくなってしまいます。
つまり、収集できるデータによりデータ活用の“幅”が決まると言っても過言ではありません。それだけに「データ収集」はデータ活用の成否を左右する大切な第一歩になります。
データ収集には“信頼性重視”と“量重視”のアプローチがある
データ活用がうまくいっていない事例をみると、収集したデータの量や信頼性の不足が要因である場合が数多く見られます。
データの量が多ければ多いほど情報活用が進む可能性は広がります。ですが、量が膨大でも、ほとんどが信頼できない情報であれば、実際に使えるデータ量は少なく、高いレベルでのデータ活用は望めません。逆に、データの量が少なくても信頼できる情報であれば、高いレベルのデータ活用が期待できます。
つまりデータ収集の戦略は、(1)信頼性重視型と(2)量重視型に大別できます。図1は、データ収集戦略のアプローチの違いを、ろ過装置に例えたものです。
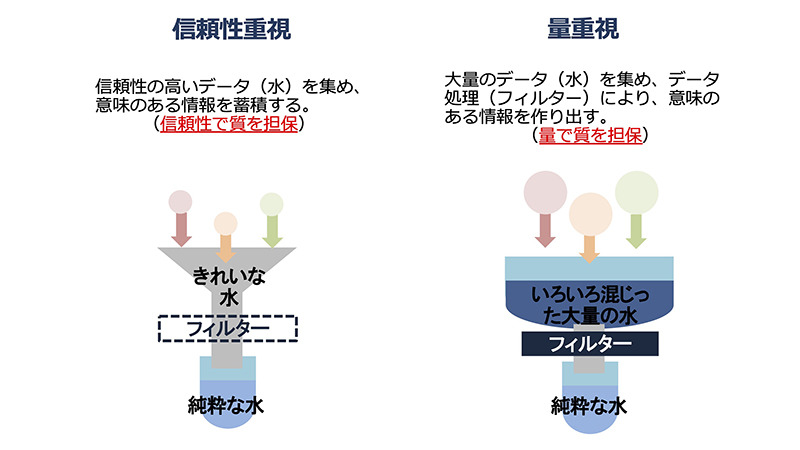
信頼性重視型 :たとえ量は少なくても、元々きれいな水(信頼性が高いデータ)を集め、必要に応じてフィルターでろ過することで、純粋な水(分析に使えるデータ)を得るイメージです。量は少なくても意味のあるデータを蓄積するというアプローチです。
例えば医療領域であれば、難病患者の情報収集が挙げられます。難病患者は、そもそも人数が少なく、得られる情報量が限られます。そのため、データを長期間、丁寧に収集し、できるだけ信頼性の高いデータを蓄積し活用します。難病治療薬の開発では、信頼性重視型のアプローチによる成功例があります。
量重視型 :個人に紐づいているデータです。モノのデータがヒトに結び付いている場合も同様です。パーソナルなデータを取り扱う場合は、個人情報に関連する法令やガイドラインを遵守した特段の配慮が必要になります。
水が、きれいか汚いか(信頼性が高いか低いか)はあまり考えず、とにかく集め、フィルターにかけることで純粋な水を得るイメージです。ただしフィルターのかけ方によっては、純粋な水があまり得られないことがあります。
量重視型は、データの信頼性を“量”で担保するアプローチです。第1回で触れたビッグデータの分析が代表例です。種々雑多なデータを分析・解析し有用な知見を産み出そうとします。ビッグデータの分析は、種々のBI(Business Intelligence)ツールやデータマイニングツール、AI(人工知能)技術の発達により、利用しやすくなってきています。
例えばヘルスケア領域では、ウェアラブルデバイスなどを使って運動や睡眠といった日常データを収集することで行動を可視化することが一般的になってきています。より多くの個人の日常データをクラウドに集積・解析することで疾病リスクを導出することも可能になっています。