- Column
- 信頼できるAIのためのAIガバナンスの実戦的構築法
信頼性を高めるためのAIセキュリティ【第7回】

前回は、AI(人工知能)ガバナンスを効果的に進めるためのAIインベントリーとAI開発プラットフォームについて解説した。今回はAIセキュリティ、なかでもAIシステムに対するサイバー攻撃と対策強化の必要性に焦点を当てて解説する。
生成AI(人工知能)の登場により、企業などのデジタル化への向き合い方が変わってきた。業務のDX(デジタルトランスフォーメーション)においても、AI技術を活用する場面が多くを占める状況になりつつあるのではないか。少なくとも、生成AIによる現実感のあるデジタル化施策への発展や、早い段階での商品化による利用環境の整備、企業内での、いわゆる“民主化”の進展など、AI技術の存在感が高まっていることは間違いない。
新たなテクノロジーが登場すると、必ずと言ってよいほどデータの取り扱いやサイバーセキュリティの問題が浮上する。従来型の機械学習(ML:Machine Learning)モデルや生成AIに代表される深層学習(DL:Deep Learning)モデルといったAI技術も同様だ。生成AI登場後は、主に以下のようなセキュリティ上の論点が顕著になった。
論点1 :AIシステムへのデータ入力などを通じた個人情報や機密情報の漏えい
論点2 :AIシステムによるランサムウェアなどの自動生成や拡散=サイバー攻撃の急増と、さらなる巧妙化
論点3 :AIシステムに対するサイバー攻撃と対策強化の必要性
これらの他にも、AIモデルにおける学習データの権利問題や、サイバー攻撃からの防御・検知対策へのAI技術の導入など、派生する議論は多い。以下では、AIガバナンスの重要な構成要素である第3の論点「AIシステムに対するサイバー攻撃と対策強化の必要性」に焦点を当てて解説する。
AIの特性に合わせた技術的セキュリティ対策が不可欠
AIシステムに対するセキュリティ対策について「通常のセキュリティ対策と何が違うのか」という疑問を持つこともあるだろう。
その点では「情報セキュリティ」と呼ばれていた時代から、サイバー攻撃の防御に象徴されるサイバーセキュリティにおいても、守るべき対象(データ)、人の行為や攻撃手法(脅威)、堅牢ではない対策(脆弱性)をもってリスクを認識することが基本であることに変わりはない。それぞれの特徴や特性を考慮しなければ、効果的な対策は講じられないからだ。
だがAIシステムに対するセキュリティ対策では、守るべき対象が従来とは異なることと、AI特有の攻撃手法が存在することに注目する必要がある。すなわち、AIモデルやAIシステムであるがゆえに「そのための技術的なセキュリティ対策が必要である」というのが結論だ。
日本企業の多くは、AIシステムに関わるリスクとして、出力内容の正確性や、システムとしての信頼性に関する懸念を抱いている。KPMGが実施した『サイバーセキュリティ・サーベイ2025』でも、AI技術の導入リスクとしては「アウトプットの正確性」を挙げる企業が40.2%と最も多い。それに「プライバシー侵害」(36.1%)「アウトプットへの偏見」(32.0%)「不正もしくは有害な利用」(27.8%)が続く。「サイバーセキュリティリスク」は25.8%で5番目に登場する(図1)。
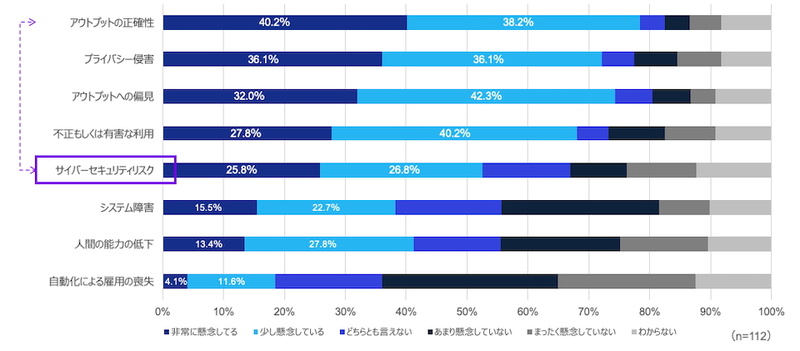
サイバーセキュリティでは、データの窃取や漏えいの被害を想起しがちだ。だが、誤作動や意図しない結果の出力など、人が識別できないように変えられてしまうAI特有のリスクにも着目すべきである。
このような特徴や傾向を考えれば、実際には回答が最も多かった「アウトプットの正確性」への懸念には、サイバーセキュリティリスクに起因するものが含まれるとも考えられる。それ以外にも、事実とは異なる内容や文脈と無関係な内容を生成するハルシネーション(幻覚)など、正確性には、さまざまな要素が含まれている可能性もある。
一方で筆者が知る限りにおいて、米国など海外の先進的な企業と比較すると、日本企業のAIセキュリティへの関心や認識は総じて高くはない。AI技術の進化の系譜を辿れば、先進国および国際機関が定める諸原則やガイドラインなどには、サイバーセキュリティリスクの懸念と、その対応の必要性が見て取れる。日本においても今後は、ユースケースが増えるにつれ、サイバーセキュリティリスクの認識は高まっていくだろう。