- Column
- データ分析/生成AI活用を成功に導くためのデータ連携入門
仕組みの“間に落ちている業務”は構造を整理する【第7回】
システム化の第一歩はデータにアクセスできるかどうか
そもそもシステム化を考える際に最初に確認すべきは「データにアクセスできるかどうか」です。
API(Application Programming Interface)でデータが取得できる、データベースから参照できる、ファイルとして出力できるといった手段があれば、データの集計・加工・反映の多くはETL(Extract:抽出、Transform:変換、Load:書き出し・格納)ツールやバッチ処理により定型化が図れます。
こうした方法の利点は(1)再現性が高い、(2)処理内容が見える、(3) 監査に耐えやすいという点です。業務が人に依存しなくなり「いつ・何を・どう処理したか」を説明できるようになります。このアプローチは、単なる効率化を超え、経営上のメリットをもたらします。
メリット1=再現性とデジタル監査 :手作業によるExcelによる処理と異なり「いつ・どのデータに・どんなロジックで」処理したかのログが残り、監査に耐えうる透明性が確保できる
メリット2=ブラックボックス化の解消 :「特定の担当者にしか分からない処理」という属人化のリスクを排除し、業務の所有権を個人から組織に取り戻せる
ただ全てのシステムがAPIやデータベースアクセスを提供しているわけではありません。その場合に選択肢に挙がるのがExcelマクロやRPA(Robotic Process Automation)です。データ加工をExcelマクロに任せる手法は伝統的によく採られてきました。
一方のRPAは画面上での操作を自動化できる反面、UI(User Interface)の変更に弱い、処理がブラックボックス化しやすい、という課題があります。そのためRPAを使う場合は「データの取得だけ」「定期実行だけ」など役割を限定するのが現実的です。
さらにAI(人工知能)エージェントが登場したことで「人がやっていた操作を自然言語を使って自動化できる」可能性が広がっています。これにより、RPAの実装が容易になる、暗黙的な手順を再現しやすくなる、といった変化が期待されています。
システム化はツール選びではなく業務構造の整理から
ただし、システム化の本質は変わりません。どうしてもデータを取得できない部分をAIエージェントやRPAで補い、それ以外は定型処理として仕組みに落とし込む。最終的に目指すのは「人が考える部分」と「仕組みが回る部分」を明確に分けることです。
すなわち、間に落ちてしまっている業務のシステム化を図るには、新しいツールを導入する前に(1)業務を分解する、(2)データで解ける部分を見極める、(3)人が関与すべき判断を切り出すという構造の整理が欠かせません。
AIエージェントやRPAは強力なツールですが、システム化の成否を分けるのは、業務とデータの構造を理解しているかどうかです。システム化の真の目的は「楽をすること」だけではないということです。
誰がどう処理したのか分からない“間に落ちている業務”が放置されている状態は、ガバナンスの欠如を意味します。これらが仕組み化され、透明性が確保されている状態こそがデータの信頼性に、そして企業の信頼性に直結します(図2)。
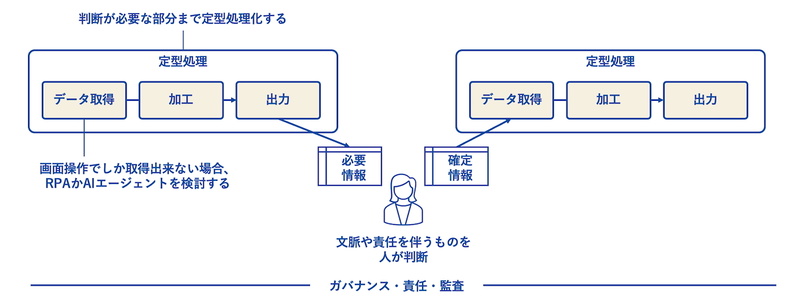
生成AI技術の活用が本格化するこれからの時代、AIモデルに学習させるデータの正しさは、こうした地道な“構造の整理”と“システム化”の積み重ねによって保証できます。“間に落ちた業務”を拾い上げることは、AI時代の強固なデータ基盤を築くことそのものです。
高坂 亮多(こうさか・りょうた)
セゾンテクノロジー CTO(Chief Technology Officer:最高技術責任者)。2007年新卒入社、2025年より現職。流通業向け業務アプリケーションの開発を皮切りに、クラウド移行やモバイルアプリケーション、コグニティブ技術を活用したアプリケーションなど先端技術領域の開発をリードしてきた。近年はデータエンジニアとして分析基盤の構築やAI活用プロジェクトを推進している。