- Column
- 課題解決のためのデータ活用の始め方
データを探せる・使える状態に保つ「データカタログ」【第8回】

前回は、収集・蓄積したデータを可視化するBI(Business Intelligence)ツールについて解説しました。BIツールによるデータ活用がある程度進んでくれば必要になるのが「データカタログ」です。今回は、データカタログが必要になる理由や、その整備・運用について解説します。
データ活用が組織に広がれば広がるほど、データが持つ意味や、その出所などを知る必要性が高まってきます。そうしたデータの意味などを管理する仕組みが「データカタログ」です。
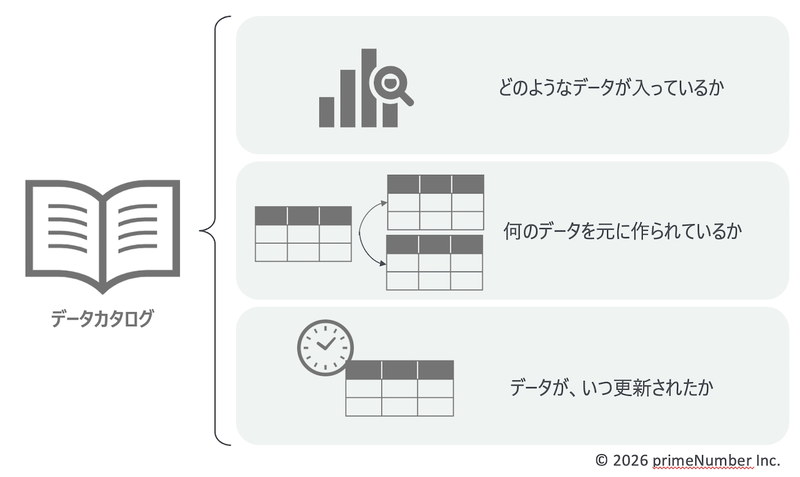
データカタログは、DWH(Data Warehouse)などのデータベースシステムに格納されているデータに対し「どのようなデータが入っているか」「何のデータを元に作られているか」「データが、いつ更新されたか」といった情報を一元的に管理する仕組みです(図1)。
データカタログが管理するのは“データの中身”ではなく“データを説明するための情報”です。これを「メタデータ」と呼びます。例えば「顧客データのテーブルには何の情報が格納されているのか」「各列(カラム)には、どのような値が入りうるのか」といった情報が該当します。
データカタログがなければ“データの定義”が不明瞭に
データカタログが整備されていないと次のような問題が発生します。
問題1:データの中身が分からない
あるテーブルに「gender」という列があるとします。記録されている値を見て「man」「woman」とあれば、この列が「性別」だと推測できます。しかし、技術的な制約や命名規則がないといった理由から「var1」や「column1」のような名前が振られていたらどうでしょう。この場合、列名だけでは内容は推測できません。値が男女の区分値として「1」「2」などと記録されていれば、何のデータかが分からないケースもあります。
列に格納されているデータを確認するにしても一部のデータを見るだけでは全貌を把握できません。例えば「男性」「女性」「不明」の3種の値しかないと想定しているカテゴリーに「未定」などイレギュラーな値が混入していても、一部のデータだけでは気づけません。データサイズが巨大になっている最近の傾向を考えれば、中身を理解するために全てのデータを確認するのは現実的ではありません。
問題2:データ定義書が陳腐化する
データベースのテーブル構造や各カラムの意味は従来、表計算ソフトウェアや文書作成ソフトウェアなどを使って「データ定義書」として管理されてきました。ただ、システムを改修するたびにドキュメントを更新する必要があり、更新を忘れると定義書の内容が実態とかい離してしまいます。
例えば、販売管理システムなどで、食品を扱うようになったタイミングで取引データに「賞味期限末日」の列を追加したとします。この時、データ定義書が更新されなければ、後にデータを分析する担当者は「データが定義書に記載されているより1列多い」という状況に直面します。その列が何の意味を持つかを突き止めるためだけに無駄な工数が発生します。
表計算ソフトウェアなどでデータ定義書を管理していると、バージョンが乱立したり、特定の担当者のPC内にしか存在しなかったりといった問題も発生します。
AI時代を迎えデータカタログがより重要に
こうしたデータ理解の問題を解決するのがデータカタログです。システムとしてメタデータを一元管理するため、常に最新の情報を組織全体で共有できます。
近年、データカタログが重視される背景には、データの活用環境の変化があります。かつてデータベースの中身を理解する必要があったのは、システムを開発・保守するエンジニアだけでした。エンドユーザーには加工済みのデータが届けられ「どのテーブルの、どのカラムを集計するか」を自分で考える必要はありませんでした。
それがBIツールの普及に伴い、営業担当者や企画部門のビジネスユーザーがデータを分析するようになりました。英数字の物理名しか持たないテーブルやカラムの中から、必要なデータを自分で探し出さなければならないとすれば、生産性は著しく低下します。
昨今はデータ活用へのAI(人工知能)技術の適用が注目されていますが、そこでもデータカタログは重要な役割を担います。AIシステムでデータを扱うには「このテーブルには何のデータが入っていて、どのような意味を持つか」をAIシステムが理解できなければなりません。そうした情報がなければAIシステムはデータすら読み取れません。データカタログの整備は、AI技術を適用したデータ分析の基盤になるのです。