- Column
- 学校では学べないデジタル時代のデータ分析法
デジタル時代はなぜ“データ分析力”を求めるのか【第1回】
データを取り扱うには、次の3つの能力が必要である(図2)。
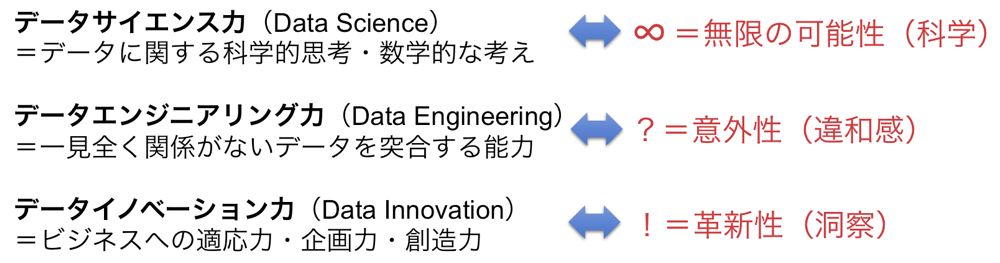
・データサイエンス力:IT、情報処理、AI活用、数学、統計学、確率論、微積分、アジャイルによるプロトタイプ開発など
・データエンジニアリング力:DIKW(Data、Information、Knowledge、Wisdom)の理論、数学的な考えを産業界で応用できる力、一見全く関係ないデータを突合する力、違和感・変曲点・特異点を知る力、トポロジー分析、スパースモデリング、ベイズ推定など
・データイノベーション力:ビジネス課題への適応力、社会変革への企画力・創造力、リスク管理力、サービスデザイン思考、ロジカルシンキングなど
データサイエンス力を重視しているのがデータサイエンティスト(Data Scientist)であり、データエンジニアリング力を重視するのがデータアナリスト(Data Analyst)やコンサルタントである。そしてデータイノベーション力を重視するのが、最近注目されているCDO(Chief Digital Officer)である。
ツールは大きく3つのカテゴリーに分けられる
冒頭、ツールありきではダメだと指摘したが、ツールが不要という訳ではない。データ分析に当たっては、ツールのカテゴリーを十分に知って“偽の力”しか持たない製品を見抜く力も必要になる。データに関連するツールは大きく次の3つのタイプに分けられる(図3)。
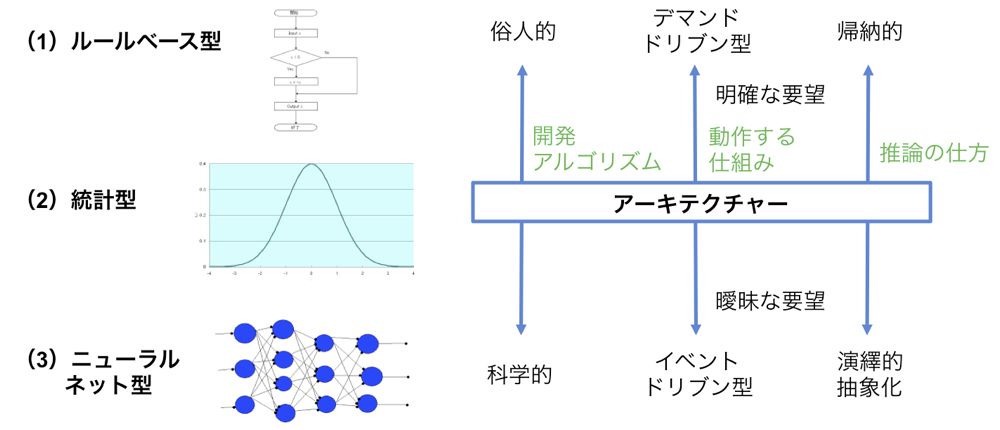
(1)ルールベース型:人が作った規則に基づいて分析する
【長所】比較的安い、構築しやすい
【短所】古いアーキテクチャー(設計思想)で科学的ではない
【特徴】俗人的、デマンドドリブン型(あらかじめ要望が明確)、帰納的
(2)ビッグデータ型(統計型):データを集めて統計処理し、その辞書に基づいて分析する
【長所】漏れなく処理、ハードウエアはCPU(Central Processing Unit)で十分
【短所】統計の辞書に依存、データ数次第
【特徴】統計的、ビッグデータ、演繹的
(3)ニューラルネット型(AI型):推論モデルを礎にAIが深層学習で分析
【長所】論理的でスムーズな処理
【短所】学習が不十分だと漏れがある、ハードウエアはGPU(Graphics Processing Unit)が適するが高価。GPUはリアルタイム画像処理に特化した演算装置で最近はAIでも注目されている
【特徴】科学的、イベントドリブン型(事前の要望が曖昧)、抽象的
現状、販売されているツールの多くは(1)ルールベース型だ。一部が(2)統計型であり、最近は(3)ニューラルネット型が「AI」として話題になっている。ただAIは、ベイズの定理などに基づいた主観的な処理のため、条件を設定した際に捨てるデータが多数あり、データの全量からすると、まだまだ漏れがある。そのため完全な処理のためには統計型ツールも必要になる。データを捨てるということはリスクの部分も増える。データ分析ではリスク管理のノウハウも重要になる。
一般に欧米発のツール類は、従来型の日本企業にとっては、使い方の問題もあるかもしれないが、適合度は低いことが多い。その背景には、日米欧の考え方における以下の違いもある。
日本:帰納的 米国:演繹的 欧州:抽象化
あくまでも例え話であるが、1~10までの合計を求める場合、日本人は1 + 2 + 3 + ・・・ + 10と帰納的に答えを出す。10まで程度なら良いが、1万までとなれば骨が折れる。米国人は結果を知っていて、演繹的に{ n × ( n + 1 )} / 2と計算で答えを出す。昔から著名な数学家を排出している欧州人は、なぜ合計が{ n × ( n + 1 )} / 2になるかを物事を抽象化して考えて理解しているとされる(1〜nまでの合計Sn = { n × ( n + 1 )} / 2 であることは、学校で習っているはずなので、読者も改めて証明してみてほしい)。