- Column
- スマートシティのいろは
「二層分離」によるスマートシティが求める市民開発とデータ連携基盤【第39回】

前回、スマートシティの実装に向けて、技術導入の前に問うべき「都市の前提条件」を再定義し、成長と持続可能性を両立するための新たな都市モデルを提言した。今回は、その制度基盤の上で都市を動かすためのデータと“主役”とに焦点を当てる。AI(人工知能)前提時代を迎え、大手ITベンダーでも中央の司令塔でもない、現場の課題を最もよく知る人々が都市サービスを担う可能性を探る。
前回、スマートシティを持続させるための制度設計として「二層分離」を示し、そこでの公的負担を(1)実験層、(2)協調領域、(3)競争領域の3層に仕分けし、それぞれに適した評価軸の設計を提言した。この構造転換なくして「補助金が切れればサービスも終わる」というスマートシティプロジェクトの悪循環からは抜け出せない。
「データの標準化」の呪縛を生成AIが解く
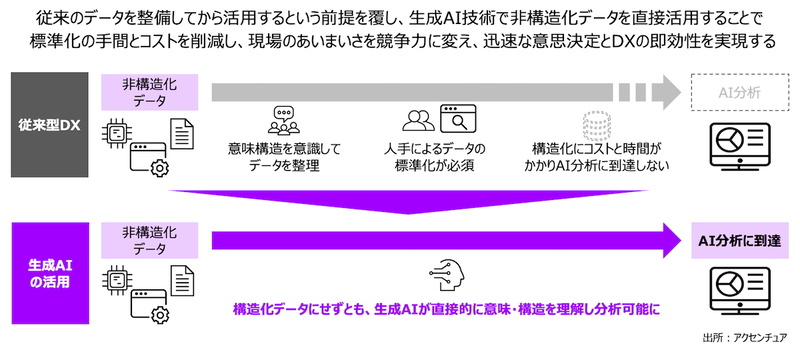
しかし制度の再構築とともに、もう1つ日本が乗り越えなければならない壁がある。「データの標準化」だ。
「デジタル化/AI(人工知能)活用に向けては、まずデータをきれいにしなければならない」--。この20年間、日本は、この呪縛に囚われ続けており“終わりのないデータ整備”へ追い込んできた。手書きの申請書や、方言交じりの日報、仕様書の消えたレガシーシステムなど、これら全てを統一フォーマットに変換しようとする「セマンティックWeb」のようなアプローチは、その膨大なコストゆえに多くの現場で挫折している。
だが今、この前提を生成AI技術が覆しつつある。エージェント型(自律型)AIなど最新のAI技術は、紙やPDF、手書きメモといったバラバラな非構造化データをそのまま読み込み、文脈を理解し、処理できるようになりつつある。いわば「ロボット掃除機のために部屋を片付ける」必要がなくなり「高性能なロボット掃除機を散らかったままの部屋に導入する」ことが可能にあるようなものだ。
例えば国土交通省は、各地の支局にバラバラな形式で提出される申請書類をLLM(Large Language Model:大規模言語モデル)で読み取り、指定項目を自動抽出してテーブル化する仕組み「LINKS Veda」を開発した。従来のOCR(Optical Character Recognition:光学的文字認識)やRPA(Robotic Process Automation)では対応できなかった多様な様式の文書を実用レベルで構造化を図っている。
これまで標準化の文脈では、日本企業の弱みとされてきた“あいまいさ”や“現場の擦り合わせ”は、AI時代にあっては障壁ではなくなる。完璧なデータベース構築を待つ必要はない。エージェント型AIに現場のデータをそのまま解釈させることで、数十年かかる標準化のプロセスを一足飛びに省略するリープフロッグが可能になる。
構造化データであっても、人間による解読が難しくいデータを生成AI技術で容易にした例もある。例えばアクセンチュアでは、ある海外の銀行において2万5000行のレガシーコードのリバースエンジニアリングの工数を生成AI技術により50%削減し、テスト効率を30%向上させた。生成AIを“通訳”にすることが、レガシー刷新プロジェクトの全体予算を大幅に削減できる可能性を示している。