- Column
- デジタルツインで始める産業界のDX
デジタルツインに必要なデータ基盤の要件(後編)【第5回】

前回は、デジタルツインの実現に必要なデータ基盤について、データ収集とストレージ、処理レイヤーを解説しました。今回は、データ基盤が備えるべき機能として、コンテキスト化、セキュリティ、データガバナンス、連携インタフェースについて説明します。
デジタルツインを実現するためのデータ基盤は、単にデータを格納し変換・加工する機能だけを提供するわけではありません。データ活用に向けては、より必要十分な管理・分析を可能にするための機能も備えなければなりません。(1)コンテキスト化、(2)セキュリティ、(3)データガバナンス、(4)連携インタフェースなどです。
(1)コンテキスト化
デジタルツインにおけるデータ活用を目指す過程で、欠かせないステップにデータの「コンテキスト化」があります。コンテキスト化とは、データが持つ意味を理解し、それを付与したり、データ間の関連性を構築したりする処理のことです。「データさえあれば何でもできる」というような誤解を持つ人もいますが、データの価値を引き出し活用するためには、コンテキスト化は不可欠です。
一般に、製造業やエネルギー産業の現場では、ベンダーが異なる様々な装置や計測システムが混在し、分析に必要なデータが複数のシステムにまたがって存在しています。これが「サイロ化」です。
例えば、工場にあるポンプ自体は、設備の1つとして設備管理システムで管理しながら、そのポンプの流量を計測した流量計の時系列データは別の監視システムが記録しているような状況です。他にも、このポンプのアラートを記録するイベントデータや、図面データが、それぞれ別のシステム上に存在するかもしれません(図1)。
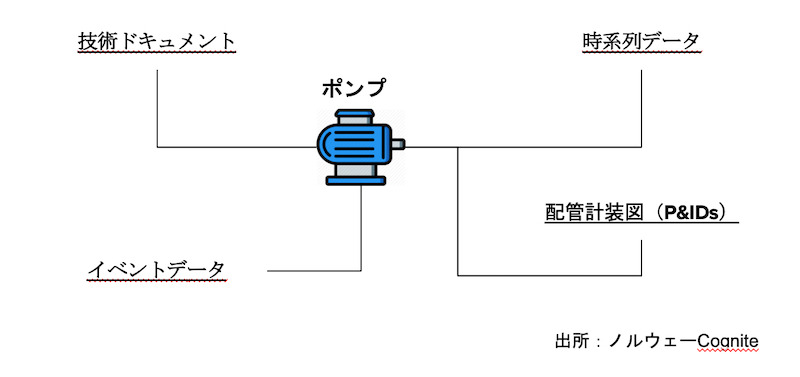
このとき、このポンプなど装置のデジタルツインを構築する際に問題になるのが、各システムが管理している装置の命名規則が一致しているとは限らないという点です。装置を特定する名称を「タグ名」と呼びますが、同じ装置に関連付けるデータにも関わらず、装置のタグ名がシステムそれぞれで異なるケースです。
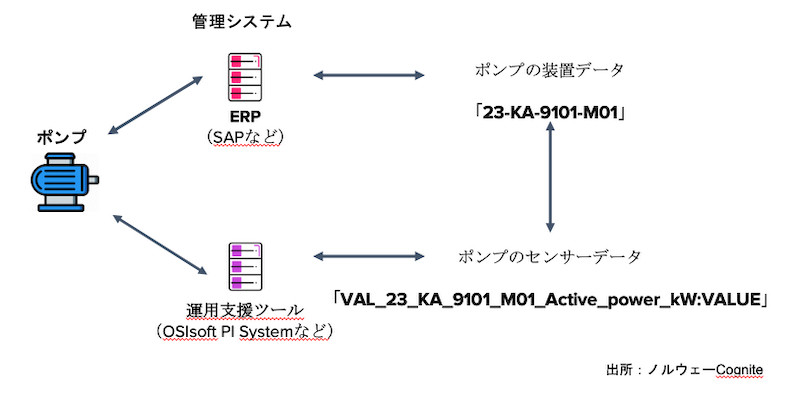
例えば、ポンプの装置データがERP(統合基幹業務システム)に格納されており、その装置のタグ名は「23-KA-9101-M01」です。このとき、同じ装置の時系列データが、運用支援ツールにタグ名「VAL_23_KA_9101_M01_Active_power_kW:VALUE」で格納されているとします(図2)。両者を、1つのポンプと見なすためには、両者を関係付けるコンテキスト化が必要になります。
コンテキスト化を実行するには、タグ名に何らかの規則性を見出したり、熟練者のノウハウによって結びつけたりする作業を実施しなければなりません。この作業を人手で実施するには時間やコストがかかります。そのため、データ基盤には、コンテキスト化の作業を支援する機能を備えていることが望まれます。
例えば、弊社Cogniteのデータ基盤「Cognite Data Fusion」であれば、「エンティティマッチング」と呼ぶコンテキスト化機能を持っています。AI(人工知能)や機械学習の技術を使って、上記作業の自動化を図ります。
ただ、コンピューターが関連付けを100%正確に実施するのは困難です。そのためエンティティマッチングでは、(1)異なるシステムが管理するデータのタグ名の規則性を機械学習を用いて発見する、(2)専門家が規則性・ルールを確認し新規ルールを作成して適合率を改善する、というステップを踏みます。ほとんどの処理は自動化し、専門家が対話的に操作できるユーザーインタフェースを用意することで、生産性を高めています。
ここまで、コンテキスト化の例としてデータ間の関連付けを取り上げました。しかしながらコンテキスト化自体は、以下のように、かなり幅広い概念を含んでいます。
・紙に印刷された図面や文書から、各ページに含まれている機器の識別情報を取り出す
・画像や映像から機器を判断する
・設備データに付随する説明の記述から機器のタイプを自動で分類する
これらの処理もコンテキスト化の有力な手法であり、データ活用を促進するために技術の改良が続けられています(図3)。