- Column
- デジタルツインで始める産業界のDX
デジタルツインを構築するための5ステップ(後編)【第3回】

前回は、デジタルツインの構築プロジェクトを進めるためには段階的アプローチが有効であり、Cogniteが実践している5つのステップのうち、ステップ1とステップ2について説明しました。今回は、それに続くステップ3〜ステップ5について説明します。
前回、デジタルツイン構築プロジェクトにおいてCogniteが顧客に提案している段階的なアプローチを紹介しました(図1)。
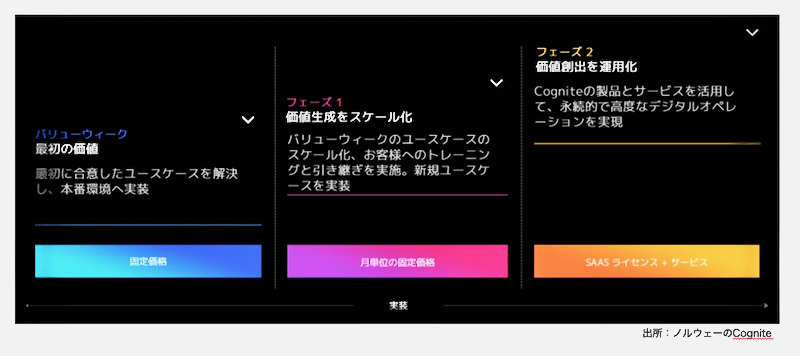
そして、この段階的アプローチでの取り組みにおける5つのステップのうちステップ1とステップ2を説明しました。それに続く、ステップ3〜ステップ5を説明します。
ステップ3:データ基盤とデータパイプラインの整備
デジタルツインの構築に向けたデータ基盤の選定は、個々のプロジェクトだけではなく、組織としてのデジタル戦略を大きく左右する要素です。アーキテクチャーから相互運用性、セキュリティに至るまで、考慮すべき要素は多々あります。鍵となるポイントをいくつか挙げてみます。
クラウドシステムの活用
データ基盤にクラウドシステムを利用するメリットは数多くあります。システム基盤の専門家に複雑な保守運用を任せられること、自動的なアップグレード、高度なセキュリティの設定と監視、柔軟なリソースの割り当て、豊富な連携オプションなどです。
デジタルツインが扱うデータは、過去の履歴データを含めると膨大な量になります。そのため分散アーキテクチャーを利用するのが基本です。複雑な分散システムをクラウドで運用できることは大きな利点です。
データモデリング
一般的に、データソースにおけるデータ構造(ソースデータモデル)と、アプリケーションの利用に適したデータ構造(ターゲットデータモデル)は異なります。ソースデータモデルにおいては、データ更新の一貫性、つまり任意の時点においてデータに矛盾がないことが最重視されることから、リレーショナルデータベース(RDB)のように正規化された形式が使われます。
一方のターゲットデータモデルでは、応答性や使いやすさが重視されるため、データの重複を気にせず用途に応じた加工済みの形式を用意するのが定石です。このデータモデルを設計・変換処理するのに必要な高速かつ使いやすいツールの充実度も決め手になるでしょう。
コンテキスト化
データ活用において、データそのものと同等に重要なのが、データの内容に関する付随情報である「メタデータ」の存在です。データが、どのシステムで生成されたか、いつの時点のデータか、他のどんなデータとどのような関連があるかといった情報です。
データに意味付けし、データを使いやすく整備する作業は「コンテキスト化」と呼ばれます。データの格納と同時に、これらのメタデータを付加・維持するためのコンテキスト化の仕組みがデータ基盤に備わっている必要があります。
セキュリティとデータガバナンス
セキュリティも、データ基盤が提供する機能として欠かせない要素です。ユーザー認証、粒度の高いアクセス制御、セキュリティ標準への準拠、安全なデータ通信はもちろんのこと、システム連携部分を含めてデータ基盤全体を高いセキュリティレベルに維持しなければなりません。
データについて責任の所在を明確にするためのデータガバナンス機能も必要です。データの管理者や加工経路を記録する一方で、データの内容や用途を明確にするデータカタログとしても利用できます。
もう1つ重要なデータパイプラインの整備については、次回で詳細に触れます。