- Column
- 生成AIがもたらすパラダイムシフト ~業務効率化から顧客体験向上まで~
開発競争が激化する生成AI、DXの実現に向けた6つの開発軸
「DIGITAL X DAY2024」より、NTT 執行役員 研究企画部門長 木下 真吾 氏
DX(デジタルトランスフォーメーション)の実現に向け生成AI(人工知能)技術を採用する動きが進んでいる。一方で、生成AI技術を取り巻く開発競争は世界規模で激化している。NTT 執行役員 研究企画部門長の木下 真吾 氏が、「DIGITAL X DAY2024 生成AIがもたらすパラダイムシフト」(主催:DIGITAL X、2024年9月26日)に登壇し、DXのためのツールとして生成AI技術を見極めるのに必要な技術動向について、NTTでの研究動向を踏まえながら解説した。
「生成AI(人工知能)技術の高性能化が進む中、用途に応じた使い分けや他のAI技術との組み合わせなどが重要になる。生成AIの利用を目的化しないためには、適切な生成AIは何か、どのように使うべきかなど、より実践的な見極めが必要になってきている」−−。NTT 執行役員 研究企画部門長の木下 真吾 氏は、生成AI技術を取り巻く環境を、こう指摘する。

その上で、DX(デジタルトランスフォーメーション)の実現に向けた実践的な見極めに際し、参考になる6つの技術動向を挙げる。(1)LLMの大規模化、(2)LLMの軽量化、(3)RAG(Retrieval-Augmented Generation:検索拡張生成)/ファインチューニング、(4)AIエージェント、(5)マルチモーダル、(6)AI専用ハードウェアだ。
技術動向1:LLMの大規模化
生成AIの性能は人間の専門家をも超えようとしている。米Googleは2023年12月、同社の「Gemini Ultra」が、数学や物理、歴史、法律など57科目を組み合わせて知識や問題解決能力を問うベンチマークテスト「MMLU」において専門家を超えたと発表した。2024年9月には米OpenAIの「OpenAI o1」が、数学や科学、プログラミングなどの分野で専門家レベルの性能を持つと発表された。
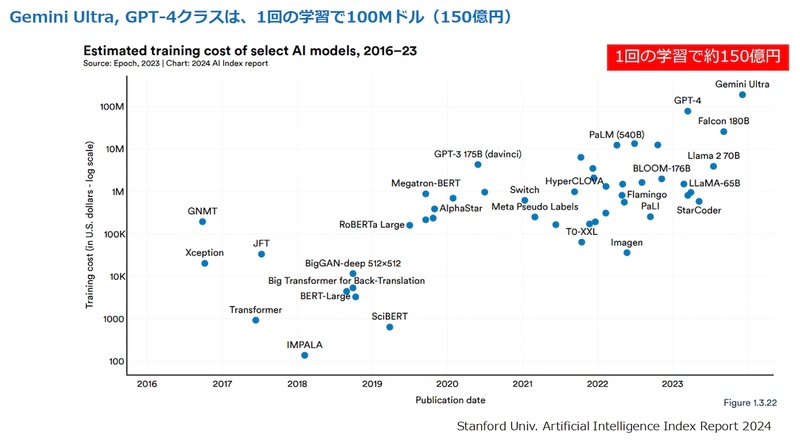
一方で、大規模言語モデル(LLM:Large Language Model)の学習コストは急騰している。Gemini Ultraの場合、1回のモデルを学習するのに約150億円のコストが掛かるとされる(図1)。しかも、その学習は1回では終わらない。学習後の本番利用でも、学習した情報を使って予測を素早く導き出す推論コストも必要である。
例えば、米Metaが開発するLLMの「Llama3.1 405B」では、「サーバーコストだけで2250万円、その他のハードウェアを合わせた総コストは7650万円と試算される」(木下氏)。これに電気代やメンテナンス代を加えれば、「とても普通の会社が維持することは難しい」(同)
電力消費量の問題もある。Open AI製LLMの「GPT-3(175B)」規模で1回の学習に1300メガワット時の電力が必要だとされる。原子力発電炉1基分の発電量が1000メガワット時と言われており、LLMの電力消費量が、どれだけ膨大かが分かる。
技術動向2:LLMの軽量化
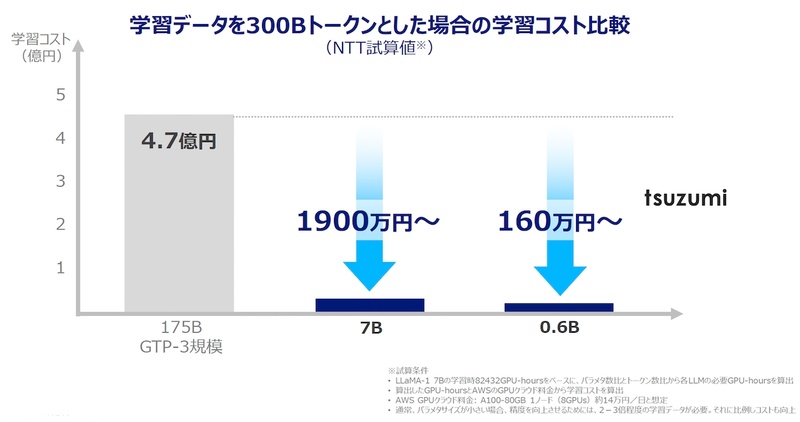
生成AIの大規模化の流れがある中で、言語モデルの「軽量化」に向けたアプローチもある。例えば、NTTのLLMである「tsuzumi」において、「軽量版のサイズは『GPT-3(175B)』の25分の1、超軽量版は約300分の1のサイズだ。GTP-3規模のLLMと比べ、学習コストも同程度に低減できる」(木下氏)とする(図2)。
軽量版であっても、「タスクを特化したチューニングにより、精度と性能を大幅に高められる」と木下氏は補足する。ベンチマークテストの平均値では、「チューニングなしのGPT-3.5に対しては約7割、同じGPT-4に対しては約5割のタスクで、それぞれ勝っている」(同)という。
軽量化に向けたアプローチには、例えば「MoE(Mixture of Experts)」や「More Agent Is All You Need」などがある。前者は、LLMの中で、句読点や接続詞、冠詞などで分類した複数の“専門家(FFN)”が分担することで稼働電力を下げながら精度を高める手法。後者は、小さいLLMを複数連携させることで精度を高める手法である。
技術動向3:RAG/ファインチューニング
RAG(Retrieval-Augmented Generation:検索拡張生成)は、LLMの回答精度を高めるために、社内データベースなどにあるLLMが学習していない情報の検索結果を組み合わせる技術である。木下氏は「試験会場に参考書を持ち込んで試験を受けるイメージだ」と例える。
一方で、ファインチューニング(FT)という手法もある。言語モデルを作る段階から社内データベースの情報などを学習させる。「参考書を使って学習し学力を高めてから試験を受けるイメージ」(木下氏)になる。
いずれもLLMの回答精度を高められるが、知識の獲得では一般に、FTよりRAGの方が適しているとされる。ただ木下氏は、「教師あり学習によりFTが高精度になる可能性があるといわれている。新規タスクの獲得や、RAGに正解がない場合、暗黙知が必要な場合などは、FTのほうが有効な可能性がある」と説明する。
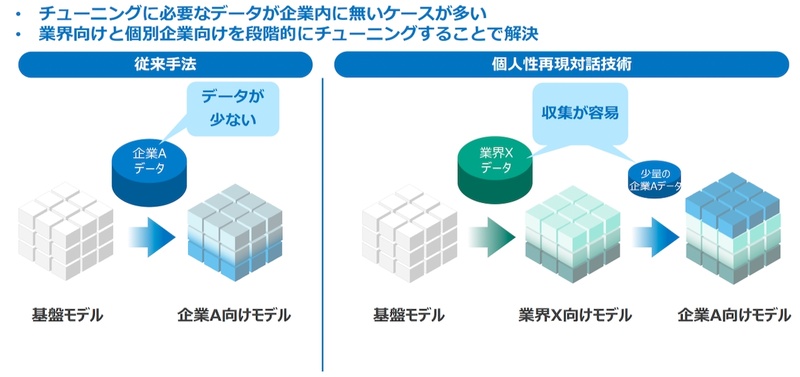
FT領域の最新研究に「階層型チューニング」がある。チューニングに必要なデータが企業内にない際に、業界データを使ってチューニングした「業界向けモデル」から「個別企業向けモデル」を段階的にチューニングする手法である(図3)。「企業内にある少量のデータでも学習効率を高め、回答精度を高められるアプローチになる。NTTでは階層型チューニングを研究している」(木下氏)という。