- Column
- 学校では学べないデジタル時代のデータ分析法
ビッグデータの法則:その4=広がる格差、なぜ格差が広がっているのか?【第23回】
IT(データ分析)の5大要素
次に、人間が処理してきたことをデータ分析の立場から見てみよう。人の生命と比較してデータ分析を考えると、人の要素と同じく5つの重要な要素がある(図3の左)。
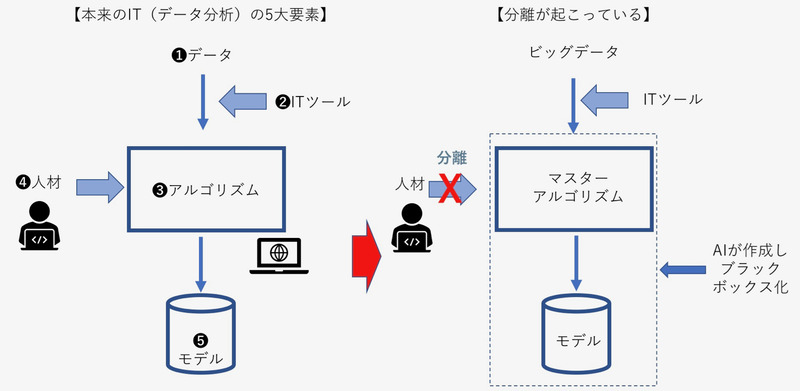
データ分析の要素1 :データ
データ分析の要素2 :ツール
データ分析の要素3 :アルゴリズム
データ分析の要素4 :人材
データ分析の要素5 :モデル(推論モデル・経験モデル)
従来、人が俗人的にデータ処理し、規範となるモデルを構築してきた。データサイエンティストのような教育を受けた人材が、適切なITツールを用いて、データを科学的に分析する。見合ったアルゴリズムを考え、データを処理し、逆問題として経験モデルを、順問題として推論モデルを、それぞれ作成する。逆問題は結果から原因を探求し、順問題は原因から結果を追究する。
データ分析にAIが介入すると、データをAIが処理するため、アルゴリズムやモデルはブラックボックス化される(図3の右)。つまり、AIがデータ分析要素の2〜5を包含するわけだ。
アルゴリズムが人間の上司になる時代
ブラックボックス化が進んだ世界では、ビッグデータとAIさえあればいい。これを5つの要素で表すと次の5つになる。これこそAI革命の本質だ。
【AI革命による変化】
(1)人が扱えないビッグデータもAIが処理する
(2)AIがツールとしてロボットなどを操る
(3)AIがアルゴリズムを考え、複数のアルゴリズムを統合し「マスターアルゴリズム」とする。
(4)AIにより人は不要になる(場合によっては教師データは人が作成する)
(5)AIがモデルを作成する
かつて産業革命で国の格差が広がった。加えて同じ国内でも職業間で格差が生じてきた。ビッグデータとAI革命では、同じ職業内でも格差が広がっていく。人々は根拠のないアルゴリズムに振り回され、AIに嫌われないような言動が求められる。AIに嫌われビッグデータに翻弄される人たちは、AIを使いこなす人から取り残され、さらに格差が広がる。まさにビッグデータの法則の1つ『広がる格差』である。
実際、配車サービス「Uber」の運転手の上司は、アルゴリズムだと言われている。乗車させた乗客がスマートフォンアプリを使ってサービスを評価するため、運転手は乗客の無謀な要求にも我慢せざるを得ないからだ。システムが自動的に生産性の悪い従業員を解雇するという会社もある。アルゴリズムに欠陥があれば人は振り回されることになる。これらも1つの格差社会であろう。
最近は、コールセンターに電話しても、すぐに問題が解決しないことが多い。コールセンターに電話するのは、自分で分かることは自ら処理するが、不明点があるためだ。だが、コールセンターの仕事はマニュアル化されており“普通”の問題しか解決できない。筆者が聞きたいような“例外的”で“難しい”質問には即座に回答できない。
これは、AIに置き換えて当面は無理であろう。コールセンターが持つノウハウを逆問題としてAIに移植しただけだからだ。ただ、AIが学習し筆者が問うような質問の回答を学んだら、それはビッグデータとして横展開できる。そのノウハウ集をコールセンターのオペレーターも共有すれば、同じように回答できる。つまり、人が今できていることはAIもできるようになる。人は新たなことに挑戦するしかない。
『〇〇する力』を養って対抗せよ
格差が広がる社会で人は、どのように対抗していけばよいのか。求められるのは、さまざまなビッグデータに対処するための『○○する力』を養うことである。筆者も「データ分析法」や「欧米の最新IT動向」などをテーマに講演する機会が少なくない。その際に感じるのは、人が必要とする『○○する力』の中でも次の3つの力が弱くなっていることである。
発想する力 :発想する力が弱いのは、「抽象化する思考力」が弱いからだ。とかく日本人は、この抽象化する力が欠けている。新しいことを創出するには、模倣から始まっても、物事を抽象化していかねばならない。
質問する力 :質問する力が弱いのは、分析が苦手で「組み立てる力」が弱いケースが多い。課題点や要望を十分に理解し、さまざまな要因を分析し、シナリオとして組み立てる。つまり、可視化・分類・予測・判別・推論・検証という分析プロセスを身に付け、そこから最適なシナリオとして組み立てる。シナリオがあれば良い質問ができる。
これは「哲学シンキング」と言う手法でも使う力だ。「何故?」「~とは何か?」という問いを重ねていく。課題の本質を質問する力で追求する方法論である。ワークショップ形式で議論する際に採用する企業が増えている。
対応する力 :さまざまな事象に対処する対応する力がないのは、知っているトレンド(流行や趨勢)が限られているからだ。可能な限り、より多くの分野の情報を把握しておきたい。言い換えると、ビッグデータを「辞書化する力」である。
これら3つの力は当然ながら、AIも弱い。だからこそ人が磨く価値がある。逆に、「認識する力」「反復する力」「記憶する力」「計算する力」はすでに、AIが人を超えている。適切なロボットなどを活用すれば「プレゼンする力」もいい勝負だろう。
たとえば認識する力は、知覚処理と認知処理からなる。画像認識や音声認識という知覚処理はAIが優れていて、ディープラーニング(深層学習)がアルゴリズムになる。一方で、常識の獲得・推論という認知処理はディープラーニングは苦手としており、記号的学習で行っている。さらにベイズの定理により、少ないデータでも処理できる。
このように複数のアルゴリズムを統合したものが「マスターアルゴリズム」である。真のAIを目指すなら、そのAIはマスターアルゴリズムを持っておかねばならない。人間に備わっているアルゴリズムは元々、統合されたものだから、結局AIは、人間のやることを模倣する必要がある。
ただAIが進化する過程では、AIを進化させるためのツールもまたAIであり、そのAIにも間違いはあるだろう。同時に、人がAIを誤用するケースも増えてしまう。AIの間違いに気付いたり、AIの誤用を防いだりするためにも、人が『〇〇する力』を養う必要がある。『〇〇する力』は分析フレームワーク「AUOODA」(第12回参照)の各フェーズでも役立つが、詳細は別の機会に譲る。