- Column
- 金融業界におけるAI時代の技術実装の道筋
生成AI時代を迎え金融業界におけるオルタナティブデータ活用が拡大
「Fintech Business Informatics 2026」より、オルタナティブデータ推進協議会 理事 北山 朝也 氏
生成AI(人工知能)技術の登場により、扱いが難しかった非構造化データを含むオルタナティブデータの活用が、金融分野においても急速に現実味を帯びてきている。オルタナティブデータ推進協議会 理事の北山 朝也 氏が「Fintech Business Informatics 2026」(主催:本プログラム委員会、共催:インプレス、2026年1月20日)に登壇し、協議会が主催したハッカソンを引き合いながら、生成AI技術を使ったオルタナティブデータの活用の可能性を解説した。
「生成AI(人工知能)技術の登場により、オルタナティブデータの活用が一気に現実的なものになった。これまで研究者が時間をかけて扱ってきた非構造化データを、実務の現場で扱える可能性が見えてきた」--。オルタナティブデータ推進協議会 理事の北山 朝也 氏は、オルタナティブデータの現在地をこう話す(写真1)。同氏はAlpacaTech 取締役 兼 ソリューション事業部 部長でもある。

生成AIの登場でオルタナティブデータ分析のすそ野が拡大
オルタナティブデータとは、ニュースやSNS(Social Networking Service)、位置情報、求人情報、気象データなど、企業活動や経済動向を多面的に捉えるための非構造化データのこと。金融分野においても、その潜在的な価値は以前から注目されてきた。
金融分野ではこれまで、株価や財務情報といった構造化データを中心に分析がなされてきた。ニュースや口コミ、メディア露出、気象などのオルタナティブデータは「価値があると分かっていながらも、分析コストや専門性の高さが壁になり、十分に活用されてこなかった」と北山氏は話す。
それが、生成AI技術が登場したことで「テキストやメタデータを要約・整理した上で、構造化データと組み合わせて検証することが、現実的なワークフローとして成立し始めた」(北山氏)。その変化を象徴するのが「オルタナティブデータを巡る関心の高まり」(同)である(図1)。
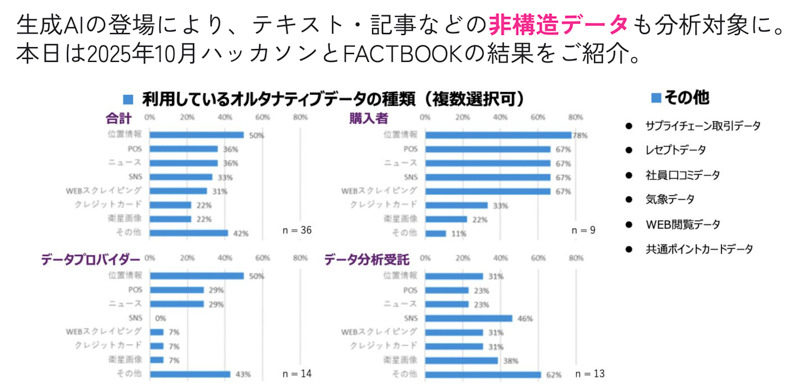
これまでも非構造化データは分析されていた。ただ「一部の専門家に限られた領域で、博士号を持つ研究者が複数人がかりで取り組んで、ようやく1つのデータを扱えるかどうかだった」と北山氏は振り返る。結果として「アイデアを試す前段階で時間とコストがかかり過ぎ、実務への展開が進みにくい構造が生まれていた」(同)という。
生成AI技術は、この構造を変える可能性がある。ニュース記事やテレビ番組のメタデータ、求人情報といった非構造化データを自然言語で扱い、要因抽出や要約、スコアリングまでが一気に可能になったことで「分析の裾野が大きく広がった。専門的なプログラミングや前処理を前提とせず『どのデータを、どの観点で見たいか』という問いを直接投げかけられる環境が整いつつある」と北山氏は強調する。
この変化を受けて2021年に設立されたのがオルタナティブデータ推進協議会だ。オルタナティブデータの活用に向けた課題を「個社で抱え込むのではなく、業界全体で解決していくことを目的に活動を続けてきた。とりわけ近年は、生成AI技術を前提にした非構造化データの活用に強い関心が集まっている。今は『どう活用できるか』を業界全体で検証するフェーズに入っている」と北山氏は説明する。
ハッカソンでは“分析に集中できる”環境を用意
オルタナティブデータの活用を実務に落とし込む際に、障壁の1つになってきたのが分析環境の構築だ。多種多様なデータを集約し、前処理を施し、分析用のコードを書き、結果をレポートにまとめる。この一連の工程には「高度な専門知識と相応の時間が必要であり、検証にたどり着くまでの大きなハードルになってきた」(北山氏)
その課題を前提から見直すためにオルタナティブデータ推進協議会はハッカソンを主催した。「分析の難しさそのものよりも、分析に入るまでの準備が難しい問題に対し、生成AI技術を前提に、構造化データと非構造化データを誰もが横断的に扱える分析基盤の構築」(北山氏)がテーマである。
ハッカソン用の分析基盤には、クラウドデータウェアハウスの「Snowflake」(米Snowflake製)と、その上で動作するオープンソースのアプリケーション開発基盤「Streamlit」を利用した。構造化データと非構造化データをSnowflakeに集約し、Streamlit上のUI(User Interface)から呼び出して分析できるようにした(図2)。
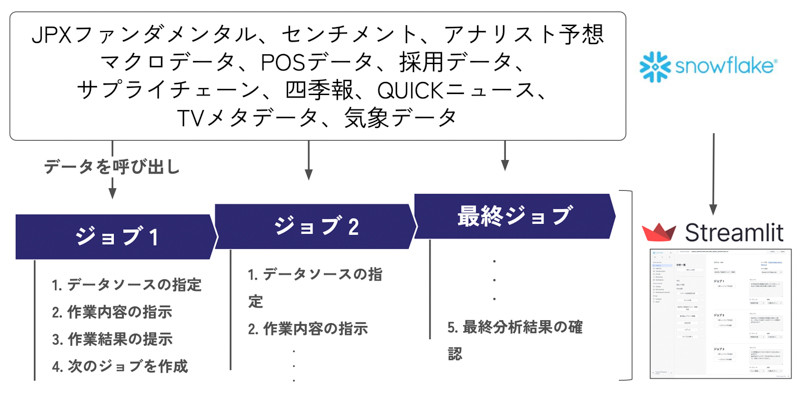
そこでの特徴は「分析の進め方そのものを“ジョブ”として定義した点だ」と北山氏は説明する。利用者は、どのデータを、どのような観点で分析したいのかを自然言語で指定すると、その指示を元に生成AIが分析を実行し、結果を次のジョブへと引き継いでいく。「ジョブを連結することで、単発の分析にとどまらず、思考の流れを止めずに、複数の視点を組み合わせた複雑な検証が可能になる」(北山氏)とする。