- Column
- 〔誌上体験〕IBM Garage流イノベーションの始め方
Reason:AI技術を活用しより良い意思決定を導く【第12回】
Garageに求められるAI/データサイエンス適用アプローチとスタンス
結論から言えば、DIKWピラミッドを逆からたどり、仮説を検証しながらスパイラルアップ的に推進するアプローチを推奨する。IBM GarageのMethodologyに重ね合わせると図4のようになる。
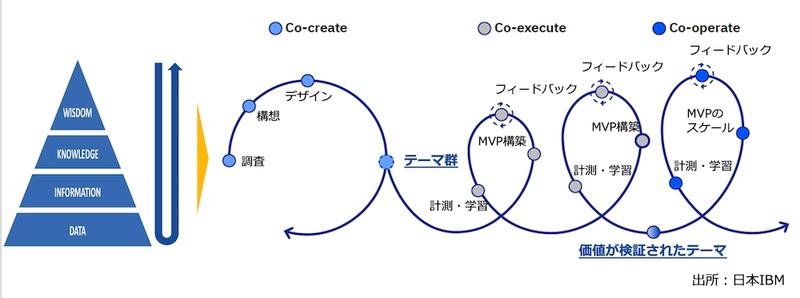
Co-Createフェーズ
Discover(第5回、第6回参照)、Envision(第7回、第8回参照)から構成されるフェーズにおいて、データサイエンティストはEnvision段階から参画することが多い。他のメンバーとともに顧客体験の価値を「Who(誰)、What(コト)、Wow(価値)」で定義し、その価値を検証するためのプロトタイプを構築しつつ、次のCo-Executeに向けて必要なAI/データサイエンス技術と、そのために必要なデータ(Information+Data)をハイレベルに書き下す。
Co-Executeフェーズ
MVP(Minimum Viable Product:実用最小限の製品)を構築し顧客価値を検証する。Envisionで描いたプロトタイプを最低限動かすためのデータとAI/データサイエンスモデルを構築する。
この段階では捨てる確率が8割程度あることを前提に、完璧なものよりもまずは動くものを作ることを重視して活動する。ユーザーにMVPをぶつけ、価値仮説を検証しながら、モデルチューニングを進め、実用最低限の評価レベルまで仕立てる。
Co-Operateフェーズ
価値が実証されたMVPをスケールしていく。実際のユーザー活用や価値創出の状況を計測しながら学習し、AI/データサイエンスモデルを磨き込むとともに、蓄積されたデータから新たな価値創出を検討していく。
以上から得た実際に起きうる状況を想定し、IBM Garageにおいてデータサイエンティストはどう行動すべきかについて、ミニ演習2と3を通じてお伝えする。
ミニ演習2
状況 :あなたは営業活動のDXを推進するGarageチームにデータサイエンティストとして参画している。現在はCo-CreateフェーズのEnvisionの最終段階にある。これまでの取り組みの中で、必要であろうデータは、基幹システム、営業支援システムのほか、営業担当者が個々に管理しているExcelシートに散在しているようだ。後続のDevelopでMVPを構築すべく、データという側面からユースケース候補を肉付けすることが求められている。あなたはどんな行動を取るべきだろうか。
選択肢 :
アクションa :既存データがどのようなものなのかをリサーチし、データの側面から実現可能なユースケースを定める
アクションb :ユースケースに求められる価値から適用すべきAI/データサイエンス技術を検討・決定し、必要データのリストを定義する
アクションc :アクションaと同bをハイブリッドで実施する。まずアクションbをクイックに描き、そのうえで時間制約の中でわかる範囲で調査を実施。優先度をつけながらサンプル的にデータを調査し使えそうなデータの目途を立てる
いずれも、状況によっては正解になるアプローチである。だが、Speed To Valueを標榜するGarageにおいてはアクションcを採用する。
ただし、アクションaとアクションbの両方を実施するためには、短い時間で単純に多くの労力を割かなければならないように見えるが、両者とも荒いレベルで“クイック&ダーティー”に進めることがポイントとなる。なぜならこの段階で完成度を高めても、次のDevelopパートで価値が実証できなければ、検証を何度も繰り返すことになるからだ。
Developでも言及した通り、ここでも使い捨てる前提で気軽に作り、ユーザーの理解を深めたり、アイデアの有効性を評価したりするために用いるといった姿勢が求められる。